4. Una aproximación geográfica a los métodos y técnicas cuantitativasN
Objetivos
- Identificar las variables de estudio cuantitativas.
- Ordenar y visualizar la información desde los procedimientos estadísticos.
- Introducir las técnicas de la estadística descriptiva en el análisis espacial.
- Indagar herramientas básicas que proporciona la probabilidad.
- Reconocer la importancia de la información cuantitativa para los estudios territoriales.
- Reflexionar sobre los alcances y los límites de la información estadística para los estudios territoriales.
Para la elaboración de esta unidad, agradecemos la participación del licenciado en Matemática Hernán de la Vega, JTP del Departamento de Ciencias Básicas de la Universidad Nacional de Luján, cuyos aportes fueron indispensables para el armado del texto.
Introducción
La Estadística aplicada suele ser muy útil para el campo de las ciencias sociales en general y en los estudios territoriales en particular porque tienen diferentes formas de enfocar la búsqueda del dato, su sistematización y validación técnica. Por ese motivo, en esta unidad nos centraremos en nociones básicas de estadística que pueden ser útiles en el momento de la formulación de una encuesta o cuando queremos volcar los datos en un mapa.
Advertimos que el uso de las técnicas cuantitativas supone el conocimiento de fundamentos matemáticos, que serán omitidos en este material didáctico porque excede los límites propuestos, para que no se convierta en un obstáculo epistemológico para los lectores.
Para cumplir con los objetivos pedagógicos de esta unidad dividimos las técnicas cuantitativas en tres grandes líneas:
- Estadística descriptiva: nos permitirá ordenar y visualizar datos que en un principio se nos presentan como desordenados y sin sentido. Podremos encontrar valores “centrales” o representativos de ese conjunto, medir su dispersión respecto de esos valores y dividirlos en porciones que nos sean útiles para nuestro estudio (todos estos conceptos quedarán más claros con los ejemplos que se muestran más adelante).
- Cálculo de probabilidades: es una parte de la matemática que estudia cómo calcular la probabilidad de que ocurran ciertos “eventos”. La probabilidad de que el próximo año haya más de tres terremotos en San Juan, la probabilidad de que al elegir diez personas de cierta población al menos una padezca dengue, etc., lo que permite planificar políticas de emergencia, acciones sanitarias o tomar decisiones económicas, entre otras.
- Estadística o estimación: esta rama de la matemática permite estimar algunos parámetros de interés para el investigador a través de una muestra tomada de una población. Así, usando una pequeña muestra se puede estimar, por ejemplo, el promedio de salarios de una gran población o el porcentaje de mujeres o la proporción de personas que votarán a cierto candidato en las elecciones, el porcentaje de mujeres trabajadoras en las quintas del valle de Río Negro, etc.
En esta unidad veremos tres tipos de ejercicios: el primero está encadenado, es decir, que para poder resolver el último ejercicio deberán previamente resolver los anteriores. Estos son los ejercicios 1, 2, 3 y 4 cuyas resoluciones están en el anexo. El segundo tipo son aquellos que están asociados a un video y que tienen la intención de fijar los conceptos (los nombraremos A, B, …). Por último, está el ejercicio correspondiente a la distribución normal, que no depende de la resolución de ningunos de los anteriores (por eso no tiene número).
A continuación, presentamos los ítems en que se divide la unidad con el objetivo de facilitar el recorrido por los temas a trabajar.
- Introducción sobre los estudios cuantitativos en la disciplina geográfica.
Estadística Descriptiva (ED):
la ED con datos sin agrupar:
- Las variables de estudio
- Cualitativas
- Cuantitativas
- Discretas
- Continuas
- Distribución de frecuencia y representación
- Medidas de tendencia central
- Medidas de dispersión
- El recorrido o la amplitud
- La varianza
- El desvío estándar
- Coeficiente de variación
- Las variables de estudio
La ED con datos agrupados
- Intervalos
- Varianza y promedio
Probabilidad
- Distribución de Frecuencias
- Distribución normal
Estimación
- Estimación de promedios y de proporciones
- Tamaño de la muestra
4.1. Introducción: el dato cuantitativo y la investigación en Geografía
Los métodos cuantitativos son aquellos que permiten la cuantificación de los datos, es decir los que podemos “contar”. Una de las técnicas más usadas es la estadística para procesar la información. Esta técnica nos va a permitir obtener, por ejemplo, la frecuencia con que ocurren los hechos o el porcentaje.
Los métodos cuantitativos en Geografía tienen una larga tradición: la crisis de las décadas de 1930 y 1940 sumada a las consecuencias de la segunda guerra mundial llevaron a que las ciencias sociales en general, y la geografía en particular, se vieran demandadas por nuevas necesidades como la planificación, en donde la técnica reinante fue el lenguaje de la matemática y la lógica. El auge de esta corriente del pensamiento geográfico, que se conoció como Geografía Cuantitativa o Neopositivista, fue en la década de 1950. Esta corriente fue ampliamente criticada a partir de los años 1960, donde nuevas líneas de pensamiento como la Geografía de la Percepción y algunas vinculadas a la Geografía Crítica comenzaron a descalificar a los métodos cuantitativos.
Hoy en día resulta anacrónico criticar o acusar de neopositivistas a los geógrafos por utilizar determinadas herramientas cuantitativas en su investigación, ya que ambos métodos –los cuantitativos y los cualitativos– complementan la manera de organizar los datos adquiridos.
Por ejemplo, cuando se realiza una investigación sobre el Instituto Geográfico Militar y se tiene por objetivo indagar sobre cuál fue la política cartográfica del Estado argentino en un periodo de tiempo, como puede ser 1904-1941, claramente no se estaría haciendo un estudio cuantitativo. Sin embargo, cuando se cuantifican las cantidades de mapas de las provincias relevadas por la institución para saber qué provincia ha sido más cartografiada, conocer las técnicas cuantitativas, como poder sacar porcentajes, enriquece la investigación. Estas técnicas nos permitirán saber que una provincia fue cartografiada 50 % más que otra.
Mazzitelli Mastricchio, M., Lois, C. y Grimoldi, N. (2015). La cobertura al descubierto, Terra Brasilis (Nova Série) [Online], 4. http://journals.openedition.org/terrabrasilis/1337
4.2. Estadística Descriptiva
Para facilitar la lectura de este apartado, los temas referidos a la Estadística Descriptiva (ED) se dividieron en dos partes:
La primera, ED con datos sin agrupar, incluye las variables de estudio, la distribución de frecuencia y las medidas de tendencia central y de dispersión.
En el segundo grupo, nos referiremos a la ED con datos agrupados, que incluyen intervalos y promedios.
Para la obtención de información comparable en la investigación geográfica, resulta relevante indagar el potencial de la estadística descriptiva como fuente de tratamiento de los datos primarios o secundarios, según requiera el criterio metodológico del proyecto. Generalmente, se intervienen datos sin tener en cuenta la rigurosidad que demanda la estadística y su representación territorial. Por ese motivo, nos detendremos en este campo señalando sus aspectos básicos.
4.2.1. La ED con datos sin agrupar
Supongamos que nos interesa estudiar cómo se distribuyen las edades de los habitantes de la ciudad de Mercedes en la provincia de Buenos Aires y nos concentramos entonces en estudiar esa variable. Comenzamos por preguntarnos cuál es la edad de cada habitante y anotamos sus respuestas. A partir de ahí, los habitantes de la ciudad de Mercedes ya no son Juan, que es rubio, y Andrea, que es tímida, a partir de ahora la población de Mercedes es 25 años, 47 años, etc. Por eso suele decirse en muchos libros de estadística que una variable es una cualidad que varía de elemento en elemento de una determinada población, en este caso la edad. Mientras que una población es un conjunto de mediciones de interés para un investigador o un conjunto de datos cuantificables conteniendo todos los valores de interés. Además, veremos que en algunos casos en donde la población es muy grande resulta cómodo (y a veces imprescindible) considerar solo algunos elementos de esa población, un subconjunto que llamaremos una muestra.
a. Las variables de estudio
Las variables suelen clasificarse en dos grandes grupos:
- Variables cualitativas: son aquellas que describen una cualidad, como la religión que practica una persona, o su nacionalidad, su color de ojos, su orientación política, etc. En otras palabras, las variables cualitativas son aquellas preguntas donde la respuesta no es numérica.
Variables cuantitativas: son aquellas cuyo valor es numérico, por ejemplo, la edad, el salario, la altura, etc. Las variables cuantitativas se dividen en:
- Discretas: son variables numéricas en las que entre dos valores consecutivos no pueden tomar ningún valor intermedio. Por ejemplo, el número de hijos de una persona puede tomar los valores 0, 1, 2, 3, etc., pero entre 0 y 1 o entre 1 y 2 no hay valores posibles, nadie va a contestar que tiene 0,7 hijos o 1,3 hijos, (en matemática se diría que sus valores son finitos o numerables). El número de terremotos en un año, la cantidad de robos en un día, etc., son ejemplos de variables discretas.
- Continuas: son aquellas en las que, entre dos valores cualquiera, la variable puede tomar cualquier valor intermedio. Por ejemplo, si estamos midiendo la cantidad de cianuro en un litro de agua de cierto río, el resultado podría ser 1 mg o 2 mg o 1,5 o 1,02 o 1,01 mg, o cualquier valor intermedio. La altura, la temperatura, etc., son ejemplos de variables continuas.
Definiciones: una variable es una cualidad que varía de elemento en elemento de una determinada población.
Una población es el conjunto de mediciones hechas por el investigador, un conjunto de datos cuantificables.
Una muestra es un subconjunto de esa población.
Tipos de Variables - Estadística para la investigación
Mente Estadística (s/f). Tipos de Variables - Estadística para la investigación [Archivo de Vídeo]. Youtube. https://www.youtube.com/watch?v=sQ08tqf-rXU
Luego de ver el video responda:
- ¿Qué es una variable?
- ¿Cuántos tipos de variables hay?
- Ejemplifique tipos de variables.
b. Distribución de frecuencias y representación
La distribución de frecuencia y de representación es la parte de la estadística que permite visualizar y ordenar los datos que tomamos en la etapa de campo y que a primera vista nos aparecen desordenados.
Veamos un ejemplo concreto con pocos datos para facilitar los cálculos. Supongamos que interesa estudiar cómo se distribuyen la cantidad de casos de dengue en 20 localidades. Luego de realizar la salida de campo y de recabar la información se obtiene que en la localidad 1 hubo 2 casos de dengue, en la localidad 2 hubo 9 casos, etc. Concretamente se obtienen los siguientes valores: 2, 9, 2, 4, 1, 0, 4, 5, 2, 1, 1, 4, 5, 4, 4, 0, 4, 5, 5, 4. En principio estos valores son una tira de datos sin sentido aparente. Comencemos la tarea de otorgarles sentido:
Llamemos “X” a nuestra variable de estudio y “N” al total de datos (total de elementos de la población) de manera tal que X = casos de dengue en cada localidad (que es una variable cuantitativa discreta) y N = 20 (en este ejemplo es la cantidad de ciudades).
Si ordenamos estos de menor a mayor obtenemos: 0, 0, 1, 1, 1, 2, 2, 2, 4, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 9. Esto permite identificar, más fácilmente, cuántas veces se repiten cada uno de los datos.
Si llamamos f (frecuencia simple), a la cantidad de veces que aparece cada valor de la variable X, podemos armar nuestro primer cuadro y nuestros primeros gráficos para empezar a visualizar los datos (Tabla 4.1).
| x | f |
| 0 | 2 |
| 1 | 3 |
| 2 | 3 |
| 4 | 7 |
| 5 | 4 |
| 9 | 1 |
La Figura 4.1 es conocida como “histograma” o “gráfico de barras” y se obtiene poniendo los valores de la variable en el eje horizontal y construyendo barras cuya altura es el valor de la frecuencia.
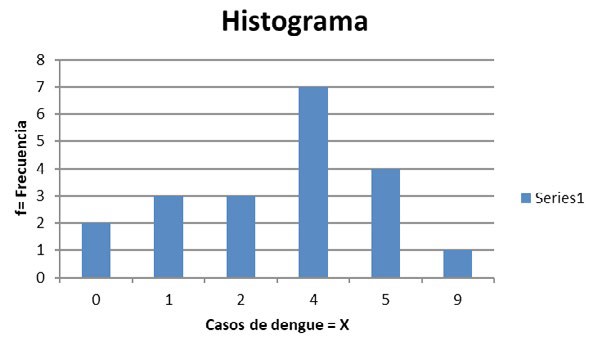
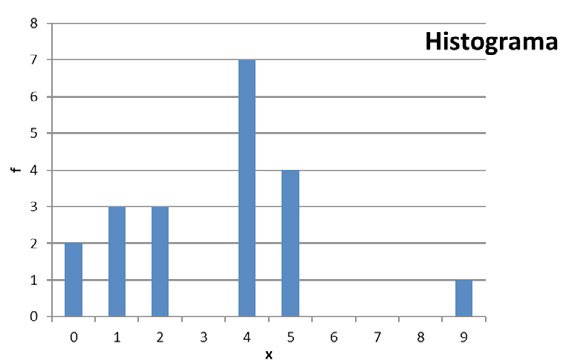
Nótese que, si bien los valores del eje horizontal están ordenados de menor a mayor, no se han completado con valores intermedios faltantes (los valores 3, 6, 7 y 8). Eso queda a gusto del que realiza el gráfico de acuerdo con lo que se quiera mostrar. De haberlos incluido, el gráfico se vería así (Figura 4.2):
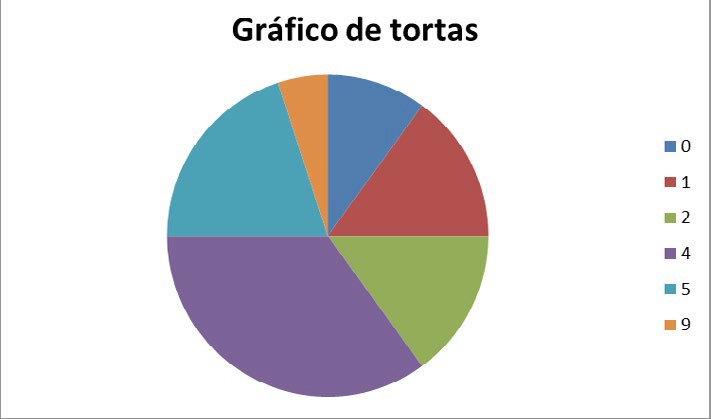
El Gráfico 4.1 se llama “gráfico de torta” o “gráfico circular” y se obtiene (si se quiere hacer a mano) repartiendo los 360° de un círculo en forma proporcional a los datos mediante una regla de tres simpleN.
Veamos un ejemplo: la porción del círculo que corresponde al valor X=2, se calcularía así:
\[ \mbox{20 datos______} 360° \]
\[ \mbox{3 datos______} \frac{3 x 360°} {20} = 54° \]
Recordemos que la regla de tres simple es una operación matemática que nos permite resolver rápidamente problemas de proporcionalidad, tanto directa como inversa.
Veamos cómo profundizar el análisis de nuestros datos. Si volvemos al primer cuadro de frecuencias simples (Tabla 4.1) podemos enriquecer nuestro análisis agregando unos pocos datos y haciendo unas cuentas simples. Llamaremos:
- Frecuencia relativa (fr) a la frecuencia simple (f) dividido el total de datos (N), o sea fr = f/N.
- Frecuencia acumulada F (mayúscula) a los números que surgen de ir acumulando (sumando) las frecuencias simples f.
- Frecuencias acumuladas relativas (Fr) a la frecuencia acumulada (F) dividido el total de datos, o sea Fr = F/N.
De manera tal que obtenemos:
| X casos de dengue |
f
frecuencia |
fr
frecuencia relativa |
F
frecuencia acumulada |
Fr
frecuencia acumulada relativa |
| 0 | 2 | 0.1 | 2 | 0.1 |
| 1 | 3 | 0.15 | 5 | 0.25 |
| 2 | 3 | 0.15 | 8 | 0.4 |
| 4 | 7 | 0.35 | 15 | 0.75 |
| 5 | 4 | 0.2 | 19 | 0.95 |
| 9 | 1 | 0.05 | 20 | 1 |
Interpretemos esos valores. Si multiplicamos las fr por 100, podemos ver esos valores como porcentajes, por ejemplo, el 0,35 del cuadro nos indicaría que el 35% de las localidades tuvieron 4 casos de dengue, el 0,15 nos diría que el 15% de las localidades tuvieron 2 casos de dengue, etc. Las frecuencias acumuladas F muestran los casos acumulados hasta ese valor de la variable X, por ejemplo, el número 15 indica que hay 15 localidades que tuvieron 4 casos de dengue o menos (como máximo 4) y las Fr indican lo mismo, pero en porcentajes, por ejemplo, el número 0,75 indica que el porcentaje de localidades con 4 casos de dengue o menos (a lo sumo 4) es el 75%.
Tabla de frecuencias agrupada en intervalos | Ejemplo 1
Matemáticas profe Alex (s/f). Tabla de frecuencias agrupada en intervalos | Ejemplo 1 [Archivo de Vídeo]. Youtube. https://www.youtube.com/watch?v=CuKr7GzohbI
c. Medidas de tendencia central
Algo de suma importancia cuando se analizan datos es intentar hallar algún valor que sea representativo de todo el conjunto, conocido como “dato “central” (con todo lo arbitrario que eso implica). Las formas más usadas para obtener este valor central son:
- El modo (o moda): es sencillamente el valor que más se repite. Podemos decir que es el valor con mayor frecuencia, y en muchas ocasiones sirve como valor representativo y en otros, no. Si vemos la Tabla 4.1 de nuestro ejemplo notamos que el valor con mayor frecuencia es 4.
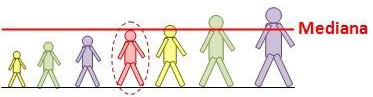
La mediana: es el valor central cuando se ordenan los valores de menor a mayor. Es el valor que deja al menos el 50% de la población a la izquierda y al menos el 50% a la derecha. En nuestro ejemplo, como teníamos 20 datos estudiados, el lugar central estaría entre el dato número 10 y el número 11. Veamos nuestros números:
\( 0, 0, 1, 1, 1, 2, 2, 2, 4, \fbox{4, 4, }4, 4, 4, 4, 5, 5, 5, 5, 9 \) así que deberíamos tomar un promedio entre esos dos valores lo que en este caso da 4.
El promedio (o la media): ejemplo sería
\[ \frac{0+ 0+ 1+ 1+ 1+ 2+ 2+ 2+ 4+ 4+ 4+ 4+ 4+ 4+ 4+ 5+ 5+ 5+ 5+ 9}{20} = 3.3\]
o más fácil \( \frac{0 \times 2 +1 \times 3 + 2 \times 3 +4 \times 7 +5 \times 4+9 \times1}{20}=3.3 \) se obtiene a partir de multiplicar cada valor de la variable por su respectiva frecuencia, sumar todos esos valores y dividirlos por el total. Esta última expresión se puede generalizar usando el símbolo matemático de sumatoria (\( \sum \)) y obtenemos la fórmula: \( \mu = \frac{\sum x \times f}{N} \)
Es importante tener en cuenta que cuando el promedio se calcula para una población se representa con la letra griega μ; mientras que cuando se trata de calcular el promedio de una muestra de la población el promedio se representa con el símbolo \( \overline{x} \).
Para calcular el promedio de una población: \( \mu = \frac{\sum x \times f}{N} \)
Para calcular el promedio de una muestra de la población: \( \overline{x} = \frac{\sum x \times f}{N} \)
Como vemos, la fórmula es la misma, solo cambia la simbología.
Dibujo de la mediana de las alturas de siete personas
Si el conjunto de datos no está ordenado, la mediana es el valor del conjunto tal que el 50% de los elementos son menores o iguales y el otro 50% mayores o iguales.
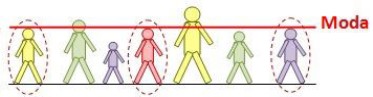
Dibujo de la moda de las alturas de siete personas
La moda es el valor más repetido del conjunto de datos, es decir, el valor cuya frecuencia relativa es mayor. En un conjunto puede haber más de una moda. El promedio es la sumatoria de alturas dividido la cantidad de personas
d. Medidas de dispersión
Una de las críticas más usuales que se hace a la estadística tiene que ver con el uso inadecuado de las medidas de tendencia central. En realidad, esa mala lectura puede interpretarse como una manipulación de los datos por parte del investigador. Por ejemplo, una persona tiene dos pollos y otra no tiene ninguno, en promedio tienen uno cada uno; sin embargo, en este caso, no se estaría mostrando la mala distribución de los pollos. Esa crítica, en realidad, se basa en cuán dispersos están los datos respecto del promedio, lo que hace que este sea más o menos representativo de la población.
Prestemos atención a lo que sucede en el siguiente ejemplo: supongamos que tenemos dos poblaciones, cada una solo tiene dos personas. En la primera población una persona gana $48 y la otra gana $52, mientras que en la segunda población una persona gana $1 y la otra $99. Notemos que en ambas poblaciones el promedio es $50, pero en el primer caso ese valor es muy representativo de lo que está pasando y en el otro no, ya que los datos están muy lejos del promedio.
\[ \begin{align*} \text{El promedio es representativo } \ \ \ \ \ \ \ \ 48 \ \ \ & \mathbf{50} \ \ \ 52 \ \ \ \ \ \ \\ \text{El promedio no es representativo } \ \ \ 1 \ \ \ \ \ \ \ \ \ \ & \mathbf{50} \ \ \ \ \ \ \ \ \ \ \ 99 \end{align*} \]
Para medir si los datos están muy dispersos respecto del promedio o poco dispersos, veremos tres medidas y un criterio que suele usarse para determinar si la media puede considerarse un valor representativo de la población o no.
- El recorrido (o amplitud): es simplemente restar el mayor valor con el menor valor. Con los datos del ejemplo: en la primera población, el recorrido es \( 52-48=4 \), mientras que en la segunda es \( 99-1=98 \). El recorrido es una medida considerada muy rudimentaria, pero permite visualizar la concentración de los datos y es muy fácil de calcular. Dicho en otras palabras: cuanto menor es el valor del recorrido más representativo de la población es el promedio; contrariamente, cuanto mayor es el valor del recorrido, el promedio es menos representativo.
- La varianza: se simboliza como \( \sigma^2 \)
si se trata de una población o \( S^2 \) si hacemos referencia
a una muestra de esa población. Consiste básicamente en restar cada valor
de la variable con el promedio, luego elevar ese valor al cuadrado (para
obtener un valor positivo), sumarlos, y por último, hay que dividirlos
por el total de datos. En el ejemplo de los salarios: en el primer caso
sería \( \frac{(48-50)^2 + (52-50)^2}{2}=4 \) y
en el segundo \( \frac{(98-50)^2 + (1-50)^2}{2}=2304 \).
Nótese que, a mayor dispersión, mayor valor de la varianza. La fórmula es: \( \sigma^2 \frac{\sum (x-\mu)^2 \times f}{N} \). En el ejemplo de los casos de dengue sería \( \sigma^2 \frac{(0-3.3)^2 \times 2 + (1-3.3)^2 \times 3 + (2-3.3)^2 \times 3 + (4-3.3)^2 \times 7 + (5-3.3)^2 \times 4 + (9-3.3)^2 \times 1}{20}=4.51 \)
Es importante tener en cuenta que la fórmula de la varianza cambia cuando trabajamos con una población o una muestra de ella:
Varianza para una población: \( \sigma^2 = \frac{\sum (x-\mu)^2 \times f}{N} \)
Varianza para una muestra de la población: \( S^2 = \frac{\sum (x-\bar{x})^2 \times f}{N-1} \)
- El desvío estándar: Se representa con la letra griega \( \sigma \) si es para una población o con s si es para una muestra y es la raíz cuadrada de la varianza \( \sigma = \sqrt{\sigma^2} \). En los ejemplos de los salarios sería \( \sigma = \sqrt{4} = 2 \) y \( \sigma = \sqrt{2304} = 48 \). En el ejemplo de los casos de dengue el desvío es \( \sigma = \sqrt{4.51} = 2.12 \).
- Coeficiente de variación (CV): es el cociente (la división) entre el desvío estándar y la media, o sea \( CV= \frac{\sigma}{\mu} \) para una población mientras que la simbología de \( CV \) para una muestra de la población es \( CV= \frac{s}{\bar{x}} \). Ambas fórmulas suelen interpretarse del siguiente modo: si este número es superior a 0,5 se interpreta que la dispersión de los datos es excesiva y que el promedio no es representativo como dato central de la población. Cuanto menor sea el \( CV \), los datos están menos dispersos y la media es más representativa.
Cortés, F. (2008). Los métodos cuantitativos en las ciencias sociales de América Latina. Íconos, Revista de Ciencias Sociales , N° 30, 91-108. Ecuador: Flacso. https://revistas.flacsoandes.edu.ec/iconos/article/view/255/251
Hasta acá hemos visto y analizados datos cuyo análisis se conoce como sin agrupar en intervalos. Sin embargo, cuando tenemos datos muy distintos entre sí es conveniente e indispensable agruparlos en intervalos. Lo veremos a continuación.
4.2.2. La ED con datos agrupados
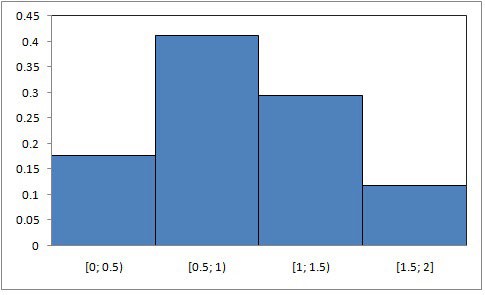
Veamos cómo agrupar los datos en intervalos. En el ejemplo de los casos de dengue (Tabla 4.1), la variable tomaba los valores de 0, 1, 2, 4, 5 y 9, recordemos, además, que estos números se tomaron para confeccionar las tablas y los gráficos (figuras 4.1 y 4.2). Es muy común, sobre todo cuando la variable toma muchos valores distintos, no mirar los datos individualmente, sino agruparlos en intervalos o “clases”. Supongamos que, por una denuncia de contaminación, queremos medir la concentración de cianuro en un río y tomamos varias muestras en las que medimos la cantidad de cianuro en un litro de agua, obteniendo los resultados (todos en miligramos): 0.01, 0.10, 0.49, 0, 5, 0.51, 0.65, 0.67, 0.78, 0.88, 0.9, 1.3, 1.31, 1.4, 1,4, 1.46, 1.6 y 1.9.
Vemos que todos los valores están dentro del intervalo entre 0 y 2, lo que matemáticamente se escribe [0;2] a su vez podríamos dividir ese intervalo en cuatro subintervalos a saber: [0;0.5); [0.5;1); [1;1.5); [1.5;2]. Los corchetes indican que el valor a su lado está incluido en ese intervalo y los paréntesis que no, por ejemplo, el dato 0.5 debe considerarse dentro del intervalo [0.5;1) y no dentro del [0;0.5). Se dice que los intervalos se toman “abiertos a derecha” (el último no lo es, ya que no hay ningún intervalo posterior que incluya un eventual valor 2).
Si bien el número de clases (intervalos) y su longitud dependen de las intenciones del investigador y de lo que él quiera mostrar, hay ciertas reglas que suelen respetarse y que se recomienda seguir:
- La longitud de cada clase es siempre la misma (en nuestro caso cada intervalo tiene longitud 0.5).
- Evitar en lo posible intervalos infinitos (por ejemplo, intervalos que contengan todos los datos mayores que un determinado valor).
- Cada dato debe entrar en una sola clase (esto debe respetarse estrictamente).
- El número de clases no debe ser muy pequeño (por lo menos cuatro) y no muy grande (no más de 20).
- Para determinar el número de clases existen varios criterios, pero uno muy sencillo y usado es el método de Kaiser que dice que este número debe ser similar a la raíz cuadrada del total de datos. En nuestro ejemplo de las mediciones de cianuro nos da \( \sqrt 17 = 4,12 \cong 4 \) clases.
Hemos visto cómo se agrupan los datos en intervalos, ahora nos concentraremos en el armado del cuadro de distribución de frecuencia.
Para armar el cuadro de distribución de frecuencias (Tabla 4.3) debemos contar cuántos datos entran en cada intervalo; por ejemplo, dentro del intervalo [1.5; 2] solo “caen” dos datos (1.6 y 1.9) y, por lo tanto, decimos que ese intervalo tiene una frecuencia f=2. Los gráficos se realizan de la misma forma que con datos no agrupados en intervalos, usando las frecuencias que figuran en la tabla. El cálculo de la media y de la varianza también se hacen como en el caso de datos no agrupados, pero se utiliza como valor de la variable X lo que se conoce como la “marca de clase”, que no es otra cosa que el punto medio de cada intervalo y que es tomado como un valor representativo de todo el intervalo (Tabla 4.3).
| Marca de clase | x | f |
| 0.25 | [0; 0.5) | 3 |
| 0.75 | [0.5; 1) | 7 |
| 1.25 | [1; 1.5) | 5 |
| 1.75 | [1.5; 2] | 2 |
Recordemos que en expresión matemática las cuentas serían las siguientes:
Promedio:
\[ \bar{x} = \frac{0.25 \times 3 + 0.75 \times 7 + 1.25 \times 5 + 1.75 \times 2}{17} = 0.926 \]
Varianza:
\[ s^2 = \frac{(0.25-0.926)^2 \times 3 + (0.75 - 0.926)^2 \times 7 + (1.25 - 0.926)^2 \times 5 + (1.75 - 0.926)^2 \times 2}{17} = 0.2041 \]
El cálculo de la moda y de la mediana cuando se trabaja con datos agrupados en intervalos es un poco más complejo que en el caso de datos no agrupados y su desarrollo se omitirá en este material didáctico. Para ampliar, puede verse:
Mendelhall, W., Beaver, r. y Beaver, B. (2010). Introducción a la Probabilidad y estadística. México: Cangage Leauning editories.
Hemos analizado la estadística (con datos no agrupados y agrupados), y vimos, entre otras cosas, cómo calcular frecuencias y promedios. La pregunta que deberíamos hacernos como geógrafos es: ¿por qué estas técnicas son importantes para expresar procesos territoriales?
Esta pregunta es bastante amplia, pero intentaremos dar alguna respuesta. Las técnicas cuantitativas son utilizadas para analizar la frecuencia con que ocurre cierto fenómeno: qué porcentaje de la población tiene dengue, es analfabeto, etc. Estas técnicas nos permitirán analizar los datos obtenidos de manera empírica y sacar conclusiones que no podríamos obtener si los datos no estuvieran procesados a la luz de la estadística. Este análisis de la información se observa claramente en la cartografía temática y su máximo exponente son los Sistemas de Información Geográfica. Recordemos que para graficar un fenómeno sobre una base espacial debemos contar con datos cuantificables.
A continuación, presentaremos dos ejercicios estadísticos que recopilan los conceptos vistos hasta ahora. Es importante poder resolverlos para continuar, ya que el resto de la ejercitación depende del resultado obtenido aquí.
Para empezar su resolución debe seguir paso a paso los temas vistos hasta acá. Las respuestas a los ejercicios se encontrarán en el anexo al final de la unidad.
Se quiere estudiar algunos aspectos de la población de enfermos de covid-19 hasta el 21/09/2020 en Argentina. Concretamente se quiere saber cómo se distribuyen las edades de esa población y el número de pacientes que necesitaron ingresar a terapia intensiva. Para ello definimos las variables X como la edad de cada paciente e Y como el grado de internación que tuvo el paciente. Para facilitar el análisis se consideran solo dos casos, que el paciente haya ingresado a terapia intensiva, evento que llamaremos I o que no haya ingresado a terapia intensiva, evento que llamaremos A (no consideraremos los casos de internados en terapias intermedias u otras internaciones menores). Es decir, la variable Y solo toma dos valores: I si el paciente ingresó a terapia intensiva, y A si no lo hizo.
Se toman al azar 121 casos de todo el país y se anota la edad del paciente y si ingresó a terapia intensiva o no. Se obtienen los siguientes resultados: (0; A), (1; A), (2; A), (8; A), (10; A), (10; A), (15; A), (16; A), (17; A), (18; A), (18; A), (20; A), (20; A), (21; A), (21; A), (22; A), (22; A), (23; A), (23; A), (23; A), (23; A), (25; A), (25; A), (26; I), (26; A), (27; A), (27; A), (27; A), (28; A), (28; A), (28; A), (29; A), (29; A), (29; A), (29; A), (30; A), (31; A), (31; A), (31; A), (32; A), (33; A), (33; A), (33; A), (33; A), (34; A), (34; A), (35; A), (35; I), (36; A), (36; A), (36; A), (36; A), (37; A), (37; A), (37; A), (37; A), (38; A), (38; A), (38; A), (38; A), (39; A), (39; A), (39; A), (40; A), (41; A), (41; A), (42; A), (42; A), (42; A), (42; A), (42; A), (43; A), (43; A), (45; A), (45; A), (45; I), (45; A), (47; A), (47; A), (47; A), (47; A), (48; A), (48; A), (48; A), (49; A), (49; A), (51; A), (51; I), (51; A), (52; A), (52; A), (54; A), (56; A), (56; A), (56; A), (57; A), (58; A), (58; A), (58; I), (58; A), (59; A), (60; I), (61; I), (66; A), (67; I), (68; A), (68; I), (68; A), (69; I), (73; I), (75; A), (76; I), (77; I), (78; A), (84; I), (85; A), (88; I); (88; I), (90; I), (95; I), (96; I)
Por ejemplo, el último de los datos indica que se trata de un paciente de 96 años que tuvo que ser ingresado en terapia intensiva.
Analice la variable X (edad del paciente).
- ¿Qué tipo de variable es X?
- Agrupe los datos en diez intervalos iguales comenzando en 0 y terminando en 100 y confeccione una tabla que contenga las frecuencias simples, las frecuencias relativas, las frecuencias acumuladas y las frecuencias acumuladas relativas (nota: usar intervalos “abiertos” a derecha).
- De estos pacientes ¿cuántos tienen edades entre 10 y 19 años?
- ¿Qué porcentaje de estos pacientes tiene entre 10 y 19 años?
- ¿Cuántos son menores de 60 años?
- ¿Qué porcentaje son menores de 60 años?
- ¿Cuántos tienen por lo menos 60 años?
- ¿Qué porcentaje de estos pacientes tiene por lo menos 60 años?
- Construya un histograma con las frecuencias simples.
Analice ahora la variable Y (grado de internación que tuvo el paciente).
- ¿Qué tipo de variable es Y?
- Realice una tabla de frecuencias simples y frecuencias relativas para la variable Y (esta tabla solo tiene dos renglones).
- Construya un histograma con las frecuencias simples.
- ¿Qué porcentaje de estos pacientes tuvo que ser internado en terapia intensiva?
- ¿Qué porcentaje de estos pacientes no tuvo que ser internado en terapia intensiva?
(Respuesta en el anexo)
Una vez realizado el ejercicio 1 estará en condiciones de responder el siguiente ejercicio 2.
Volviendo a la variable X del ejercicio 1 (edades en la muestra de 121 pacientes), calcule:
- La media (o promedio)
- La varianza y el desvío estándar
- El coeficiente de variación CV
(Respuesta en el anexo)
En el siguiente enlace puede verse un video sobre la distribución de casos de covid-19 en México.
En el siguiente video les presentamos un resumen del programa especial del Boletín N° 12, dedicado al análisis de la distribución y evolución espacial del COVID-19 en México y en el Municipio de Toluca, a cargo de la Dra. Marcela Virginia Santana Juárez (UAEM) y la Dra. Giovanna Santana Castañeda (UAEM), respectivamente.
- Luego de ver el video, analice cómo las autoras localizan los casos de covid-19 en el territorio mexicano a partir del uso de datos cuantitativos.
A continuación, presentamos una tabla con los datos sobre los casos de covid-19 para la Ciudad de Autónoma de Buenos Aires. Calcule los porcentajes y vuélquelos en un mapa.
Comuna de la Ciudad de
Buenos AiresCasos de covid
de marzoCasos de covid
en julio1 18 5373 2 36 1125 3 46 2293 4 10 3432 5 23 6162 6 13 2004 7 21 1182 8 4 5410 9 6 5734 10 16 1896 11 23 1418 12 22 1186 13 34 1065 15 15 1332 14 42 1673 Calculamos el promedio del número de casos para ambos meses. Luego hacemos un histograma de frecuencias relativas para ambos meses y observamos las diferencias porcentuales en cada comuna entre marzo y julio.
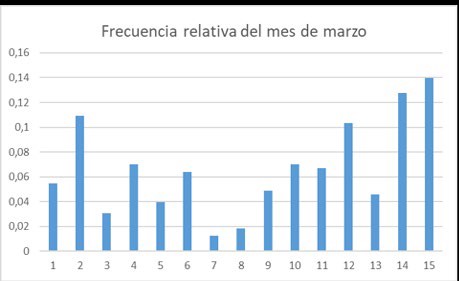
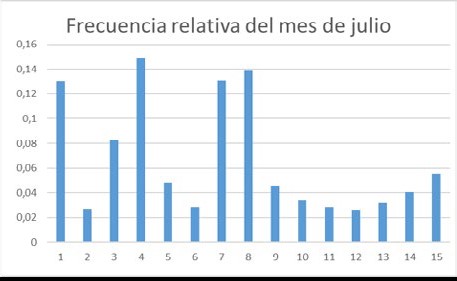
¿Se puede observar un cambio en las frecuencias relativas en algunas comunas porteñas?N
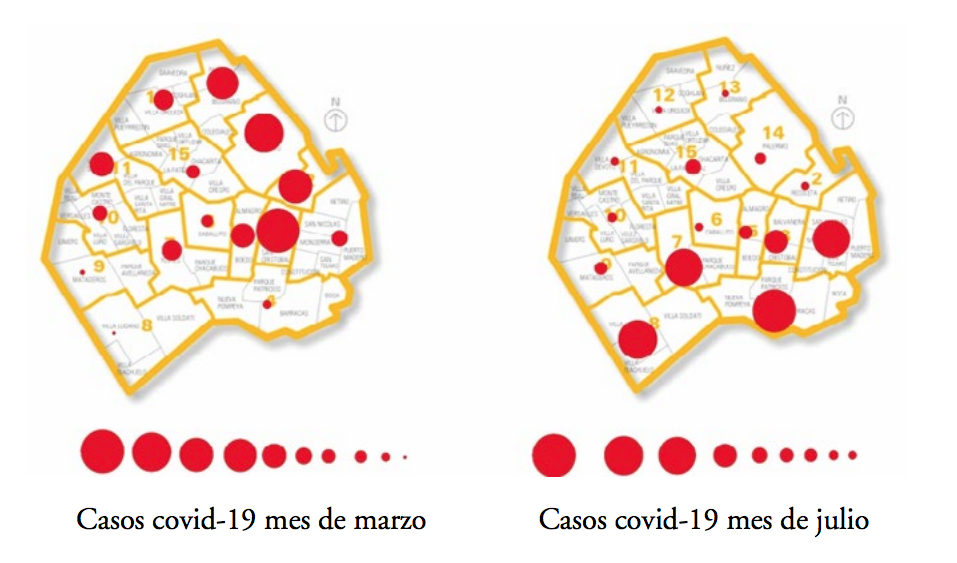 Fuente: elaboración propia.
Fuente: elaboración propia.
Recomendamos revisar las clases de Introducción a la Semiótica Cartográfica y SIG.
Aguilar Herrera, F. (2013). Métodos y Técnicas de investigación Cualitativa y Cuantitativa en Geografía. Paradigma. Revista de Investigación Educativa N° 33. https://www.lamjol.info/index.php/PARADIGMA/issue/view/211
4.3. Probabilidad
El cálculo de probabilidades es un conjunto de conceptos y técnicas que tienen por objetivo permitir calcular la probabilidad de que ocurran ciertos “eventos”. Creemos que indagar en el tema, conocer e introducirnos en la nomenclatura y en conceptos básicos de esta herramienta pueden ser de interés para la investigación geográfica.
Vamos a definir la probabilidad (P) como el cociente (división) entre los casos favorables y los casos posibles (o totales).
En términos matemáticos sería \( P = “\frac{casos \ favorables}{casos \ posibles}” \)
Reparemos en un ejemplo concreto: supongamos que estamos estudiando un universo de 50 escuelas de la provincia de Jujuy de las cuales 20 tienen problemas edilicios. Entonces, si llamamos A al evento “tener problemas edilicios” obtenemos que \( P(A)=\frac{20}{50}=0.4 \). Nótese que esto no es otra cosa que decir que el 40% de las escuelas estudiadas tienen problemas edilicios.
Así como los porcentajes varían entre 0 y 100, las probabilidades lo hacen entre 0 y 1, y es muy frecuente la conversión entre las dos cosas.
Veamos otro ejemplo: nos interesa estudiar en una población de 5000 habitantes adultos (mayores de 30 años), la relación entre la edad y su compromiso con el reciclaje de basura. Para ello dividimos nuestra población de 5000 adultos en cuatro categorías:
- a los adultos entre 30 y 45 años los llamamos jóvenes, y los representamos por comodidad con la letra J.
- a los mayores de 45 años los llamamos mayores y los representamos con la letra M.
- a los que reciclan los llamamos R.
- y a los que no reciclan noR.
Una vez encuestadas las 5000 personas obtenemos los datos que se vuelcan en la siguiente tabla.
| J | M | Totales | |
| R | 1050 | 950 | 2000 |
| noR | 700 | 2300 | 3000 |
| Totales | 1750 | 3250 | 5000 |
Recordemos que si dividimos cada número por el total (5000) obtenemos la probabilidad. De esta manera, obtenemos el cuadro de probabilidades:
| J | M | Totales | |
| R | 0.21 | 0.19 | 0.4 |
| noR | 0.14 | 0.46 | 0.6 |
| Totales | 0.35 | 0.65 | 1 |
La Tabla 4.5 se denomina “Tabla de probabilidad conjunta”, ya que los números que figuran en ella son las probabilidades de estar en dos categorías al mismo tiempo. Por ejemplo, el número 0.21 del cuadro es la probabilidad de que un individuo de la población recicle y sea joven. En símbolos P(R y J)=0.21 (que se lee: la probabilidad de reciclar y ser joven es de 0.21). Nótese que es lo mismo que decir que el 21% de los individuos estudiados recicla y es joven. De la misma forma podemos decir que el porcentaje de los que son mayores y no reciclan es el 46% (o que P(noR y M)=0.46), etc. También podemos ver, mirando los “totales” que la mayoría no recicla (solo lo hace el 40%) y que es una población con muy pocos jóvenes (solo el 35%).
¿Qué porcentaje recicla o son mayores? Aquí el conector “o” significa que puede pasar una cosa o la otra o las dos al mismo tiempo (al menos una de las dos). Podemos obtener este número porcentual de dos formas:
La primera se realiza sumando las casillas resaltadas de la Tabla 4.6 que son aquellas en las que se cumple al menos uno de los dos eventos (reciclar o ser mayor). Eso nos da 0.86 que, una vez más, podemos leer como: “el porcentaje de individuos estudiados que recicla o son mayores es del 86%” o también que “P(R o M)=0.86”.
| J | M | Totales | |
| R | 0.21 | 0.19 | 0.4 |
| noR | 0.14 | 0.46 | 0.6 |
| Totales | 0.35 | 0.65 | 1 |
La segunda forma de obtener el número porcentual es usar la siguiente regla del cálculo de probabilidades: “la probabilidad de que ocurra un evento u otro es la suma de las probabilidades de cada uno por separado menos la probabilidad de que ocurran ambos a la vez”. En nuestro caso, los eventos son R y M y la cuenta que se describió antes sería:
P(R o M) = P(R) + P(M) – P(R y M) =0.4 + 0.65 – 0.19 = 0.86 (obteniendo el mismo resultado anterior).
La probabilidad de que ocurra un evento u otro puede hacerse de dos maneras diferentes. La primera consiste en sumar los valores que comparten al menos uno de los dos eventos, en nuestro ejemplo, reciclar o ser joven. La segunda es realizando el cálculo de probabilidades, esto es, sumando todas las probabilidades de cada uno por separado y restar la probabilidad de que ocurran ambos a la vez.
Volviendo al principio, recordemos que nuestra intención original consistía en estudiar la relación entre la edad y el compromiso con el reciclaje de basura. Con ese objetivo, podría interesarnos saber, por ejemplo, qué porcentaje de los jóvenes recicla, es decir, qué porcentaje recicla no sobre el total (vemos en la tabla que es el 40%), sino dentro del grupo de los jóvenes. Podemos hacer esa cuenta como sigue: en la Tabla 4.4 vemos que el total de jóvenes es 1750 y, de ellos, solo reciclan 1050, así que haciendo 1050 dividido 1750 obtenemos 0.6 que significa que el 60% de los jóvenes recicla. Este dato puede ser relevante a la hora de planificar acciones o programas que pretendan estimular el reciclaje, ya que marca una diferencia entre el comportamiento general de la población (solo el 40% recicla) respecto del grupo de los jóvenes (en donde reciclan el 60%). Por ejemplo, si pensamos en administrar recursos para una campaña a favor del reciclaje, quizás el resultado anterior nos incline a dirigirlo con más fuerza al sector de los mayores. Hemos obtenido una conclusión importante: la edad y el reciclaje no son “eventos independientes”, la edad influye en el hábito del reciclaje.
Hay una forma de obtener el resultado anterior desde el cálculo de probabilidades:
La probabilidad de que ocurra un evento, pero sabiendo que ocurrió otro (por ejemplo, la probabilidad de que hoy llueva sabiendo que ayer llovió) se conoce como “probabilidad condicional” y se utiliza una barra vertical “|” para simbolizar el “sabiendo que”.
Así, si tengo dos eventos A y B, la expresión P(A|B) se lee: la probabilidad de que ocurra A sabiendo que ocurrió B, se calcula como \( P(A|B) = \frac{P(A \ y \ B)}{P(B)} \).
Por ejemplo, la probabilidad de que un individuo recicle sabiendo que es joven es:
\[ P(R|J) = \frac{P(R \ y \ J)}{P(J)} = \frac{0.21}{0.35} = 0.6 \]
que es lo mismo que obtuvimos antes.
Vemos además (igual que antes) que P(R|J) = 0.6 y que P(R) = 0.4, es decir que el hecho de saber que el individuo es joven influye en la probabilidad de que ese individuo recicle. La probabilidad de que alguien recicle no es la misma probabilidad de que recicle sabiendo que ese alguien es joven. Esa es la “forma matemática” de definir la independencia de dos eventos.
Más precisamente, dos eventos A y B se dicen probabilísticamente independientes si P(A) = P(A|B) , es decir, que la probabilidad de A no se altera al saber (o no saber) que ocurrió B.
Explicación de uno de los ejemplos clásicos para empezar a comprender el concepto de probabilidad, en este caso de un ejercicio de probabilidad de un evento o experimento simple en el que se utiliza la ley de Laplace.
Luego de ver el video responda:
- ¿Qué es la probabilidad?
- Imagine que tiene un dado. ¿Cuál es la probabilidad de sacar un número par?
Veamos el ejemplo con nuestros datos. Recuerde que para resolver este ejercicio deberá haber realizado los anteriores (ejercicios 1 y 2).
Siguiendo con los datos del ejercicio 1, queremos analizar la relación entre la edad y el hecho de haber necesitado internación en terapia intensiva. Para ello definimos J al evento “tener menos de 60 años” y M al evento “tener por lo menos 60 años”. Recordamos también que habíamos definido en el ejercicio 1 los eventos I (el paciente ingresó a terapia intensiva) y el evento A (el paciente no ingresó a terapia intensiva).
- Construya una tabla de probabilidad conjunta de la forma:
| J | M | Totales | |
| A | |||
| I | |||
| Totales |
- ¿Qué porcentaje de los pacientes estudiados tienen por lo menos 60 años e ingresaron a terapia intensiva? Esto es lo mismo que averiguar P(Y y B).
- ¿Qué porcentaje de los pacientes que tienen por lo menos 60 años ingresaron a terapia intensiva? Esto es lo mismo que averiguar P(I|M).
- ¿Son independientes los eventos I y M? De no serlo, ¿cómo influye uno en el otro? Es decir, el tener 60 años o más ¿aumenta o disminuye la probabilidad de haber sido internado en terapia intensiva?, ¿en cuánto?
(Respuesta en el anexo)
4.3.1. Distribución de frecuencias
Volvamos al ejemplo de los casos de dengue en donde estudiábamos la variable X= casos de dengue en cada localidad (en un universo de 20 localidades N=20). Vemos en la Tabla 4.2 de frecuencias relativas que el 10% (0,1) de las localidades reportaron 0 casos de dengue, que el 15% reportó 1 caso de dengue, etc. Dicho de otra manera, si elegimos al azar una de esas 20 localidades, la probabilidad de que en esa localidad no haya habido casos de dengue es del 10%, que haya habido 1 caso de dengue es del 15%, etc., lo que podemos simbolizar P(X =0)=0.1, P(X =1)=0.15, ..., P(X =9)=0.05.
Lo anterior se conoce como distribución de probabilidades y la podemos graficar poniendo en el eje horizontal los valores de la variable X, el número de casos de dengue y en el eje vertical la probabilidad de cada uno de esos valores (véase Tabla 4.2). En este caso, quedaría graficado como muestra la Figura 4.3. Nótese el paralelismo con el histograma original (Figura 4.2):
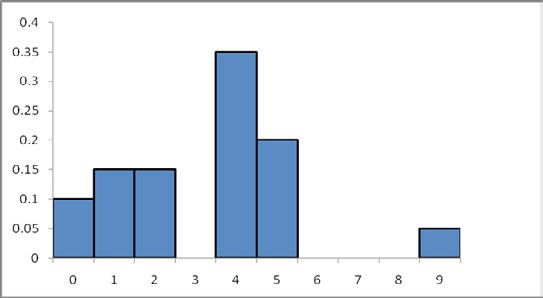
Veamos una observación que nos será útil más adelante en la comparación de variables continuas. Si quisiéramos calcular la probabilidad de que el número de casos de dengue esté entre 2 y 5 deberíamos sumar las probabilidades “puntuales” entre esos valores. Concretamente:
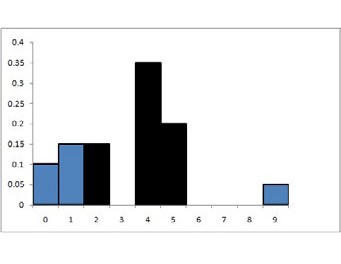
P (2< X <5) = P (X = 2) + P (X = 4) + P (X = 5) = 0.15 + 0.35 + 0.2 = 0.7
(o sea que el 70% de las localidades tienen entre 2 y 5 casos de dengue). Ahora bien, llegamos al mismo valor si calculamos el área de las barras pintadas de negro en la Figura 4.4, ya que cada rectángulo tiene como base una unidad y el área de un rectángulo es base por altura.
Cada variable (es decir, casos de dengue, número de escuelas con problemas edilicios, etc.) que se estudia tiene su propia distribución de probabilidades (su propia “forma”). Por ejemplo, en el caso que vimos sobre la contaminación de cianuro en agua, sería tal como se observa en la tabla que sigue:
Hay algunas distribuciones que ya están estudiadas debido a que existen muchos procesos y variables que se ajustan a esas distribuciones de probabilidades: como la distribución uniforme (a la izquierda), la distribución exponencial (a la derecha). Podríamos hacer una lista extensa de distintas distribuciones con nombre propio (distribución binomial, hipergeométrica, de Pascal, de Poisson, chi-cuadrado, etc.). Sin embargo, hay una distribución que sobresale de todas las anteriores: la distribución normal. Una de las razones por las que es tan importante es que muchas variables (naturales, antropométricas, psicosociales, etc.) siguen esta distribución de probabilidades y se pueden hacer cálculos usando la tabla de esa distribución (como veremos a continuación). Otra razón es que a través de ella se pueden estimar parámetros poblacionales.

4.3.2. Distribución normal
Comencemos observando la Tabla 4.7. y su histograma de frecuencias que representan las calificaciones de 100 alumnos de un establecimiento:
| x | f | fr |
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 2 | 2 | 0.02 |
| 3 | 1 | 0.01 |
| 4 | 8 | 0.08 |
| 5 | 21 | 0.21 |
| 6 | 28 | 0.28 |
| 7 | 25 | 0.25 |
| 8 | 10 | 0.1 |
| 9 | 4 | 0.04 |
| 10 | 1 | 0.01 |
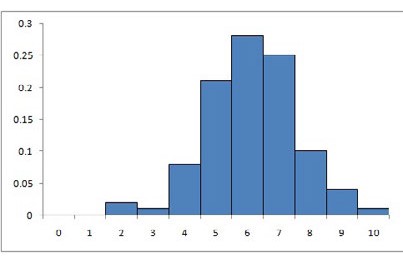
Hay una curva en forma de “campana” que ajusta bastante bien a estas probabilidades como se muestra en la Figura 4.7:
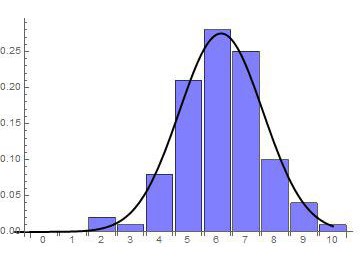
Esta curva se llama “Campana de Gauss” o “Distribución Normal”. La formulación matemática de la curva es compleja, aquí solo deberíamos verla como una curva que “reparte” probabilidades. Supongamos que queremos calcular la probabilidad de que un alumno saque un puntaje de 7 o más en el examen (el porcentaje de alumnos que sacaron 7 o más). Sumamos las frecuencias relativas del 7 en adelante, y obtenemos 0.25+0.1+0.04+0.01=0.4, o sea que el 40% de los alumnos obtuvo por lo menos 7 puntos en el examen, o dicho de otra forma P (X>7)=0.4. (véase Tabla 4.7).
Como vimos anteriormente, esto es lo mismo que sumar el área de las barras pintadas de negro (ya que la base de cada rectángulo es una unidad), pero esa área es casi igual al área bajo la campana de Gauss que “ajusta” a esas barras. Entonces podemos calcular la probabilidad anterior conociendo que área hay bajo la curva del 7 en adelante. En ese sentido es que la curva reparte probabilidades, lo hace como áreas bajo ella. Veremos de aquí en adelante cómo hallar esas áreas.
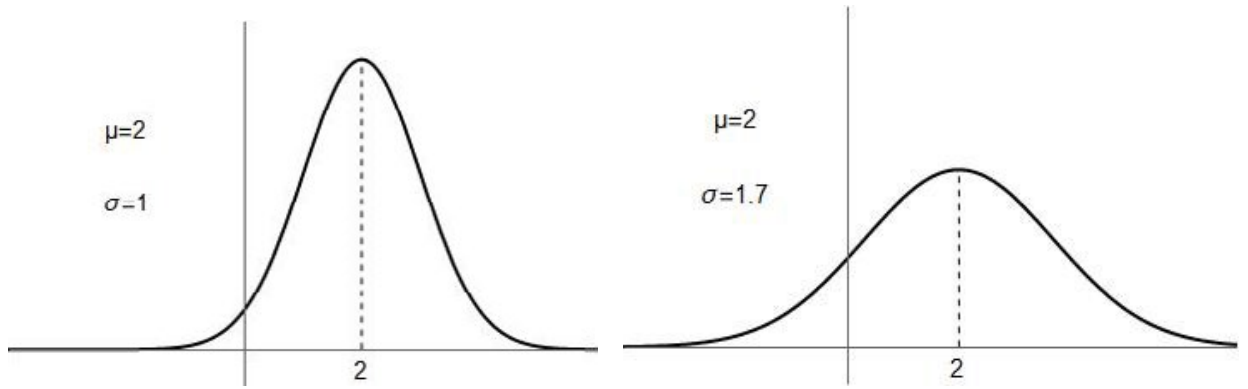
Primero, diremos que una variable “sigue una distribución normal” cuando su distribución de probabilidades se ajusta a esa curva llamada campana de Gauss. Por experiencia se sabe que muchísimas variables (sociológicas, morfológicas, psicológicas, económicas, de errores, etc.) siguen esa distribución normal. Esta distribución queda caracterizada por dos parámetros: su media (o promedio) \( \mu \) y su desvío estándar \( \sigma \). La curva es simétrica y siempre está centrada en su media y el área total bajo ella es 1, que representa el 100%. Cuanto más grande es el valor \( \sigma \), más “achatada” es la curva y cuanto más chico es ese valor más “picuda” es la curva. Por ejemplo:
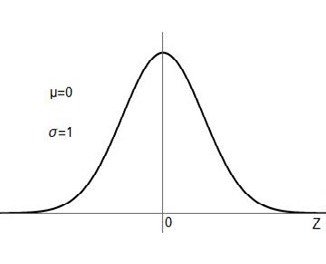
Hay infinitas de estas curvas, pero hay una que es la más importante, ya que es la única que está tabulada, que es la normal de media 0 y desvío estándar 1 (Tabla 4.8). Cuando una variable sigue esa distribución en particular se la llama “Z”. Puede demostrarse (y será de suma importancia para lo que sigue), que todas las campanas de distribución normal pueden traducirse a la normal Z, es decir, pueden llevarse a la normal de la Figura 4.9 (a la normal con \( \mu = 0 \) y \( \sigma = 1 \)).
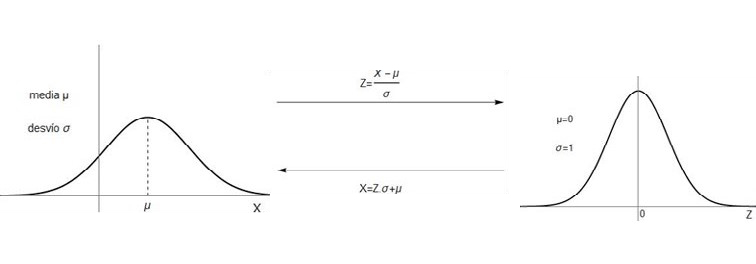
La relación exacta para hacer esta traducción es la siguiente:
Si una variable “X” sigue una distribución normal con media \( \mu \) y desvío \( \sigma \) entonces la variable \( Z = \frac{x - \mu}{\sigma} \) sigue una distribución normal con media \( \mu = 0 \) y desvío \( \sigma = 1 \). Esto se conoce como “estandarización” de la variable X (véase Figura 4.10).
En la siguiente figura se explica cómo se produce esta traducción.
Veamos con un ejemplo cómo funciona:
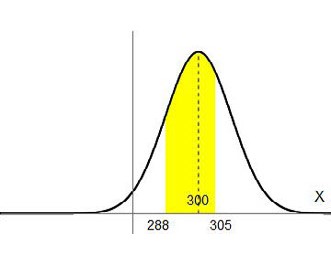
Supongamos que en una ciudad los salarios X se distribuyen en forma normal con media $300 y un desvío estándar de $100. Además, sabemos que aquellos que cobren menos de $288 son considerados pobres ¿Qué porcentaje de la población es pobre? O, dicho de otra forma, si tomo un habitante de esa población, ¿cuál es la probabilidad de que esa persona sea pobre? En símbolos queremos averiguar la P(X<288). La campana que representa esta distribución tendrá más o menos la forma de la Figura 4.11, y si recordamos que las probabilidades son áreas bajo esa curva, entonces lo que necesitamos encontrar es el área bajo la campana desde el valor 288 hacia atrás, como se muestra en la Figura 4.12:
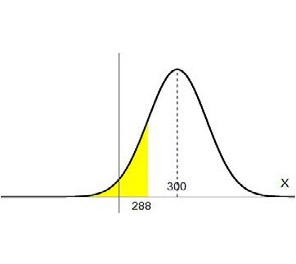
Para hallar el valor de esa área lo primero que debemos hacer es llevar esa campana a la campana que representa la distribución normal con media \( \mu = 0 \) y desvío \( \sigma = 1 \) ya que es la única que posee una tabla para hallar esas áreas (debemos estandarizar la variable \( x \)). Como se dijo antes y se mostró en la Figura 4.10, eso se hace mediante la fórmula:
\( Z = \frac{x - \mu}{\sigma} \) que en este caso sería \( Z = \frac{288-300}{100} \)
(ya que el valor X que queremos estandarizar es 288).
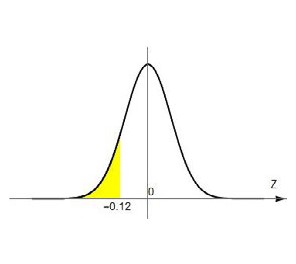
Esta cuenta nos da \( Z = –0.12 \) y significa que ahora estamos buscando (ya sobre la normal de media \( \mu = 0 \) y desvío \( \sigma = 1 \)) el área bajo la curva desde el valor \( –0.12 \) hacia atrás (Figura 4.13).
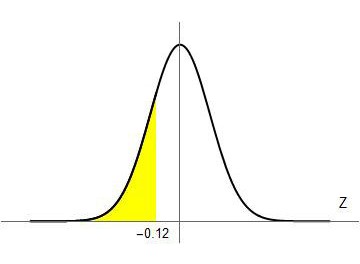
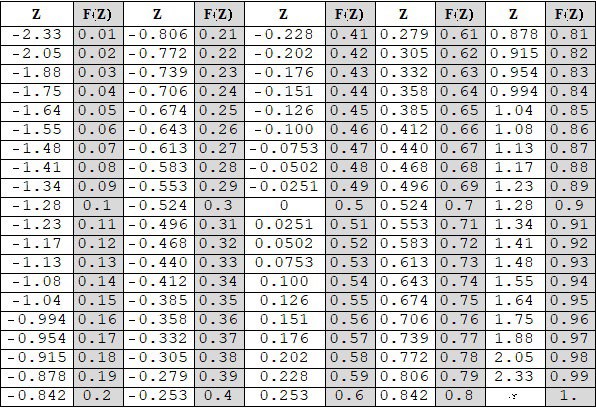
Esta área sí está tabulada y podemos buscarla en la Tabla 4.8, que para cada valor de Z nos da el área bajo la curva desde ese punto hacia atrás (por convención a ese valor se lo llama F(Z).
En nuestro caso, si buscamos el valor de la tabla más parecido a \( Z = –0.12 \) encontramos que el área que buscamos es 0.45, que nos indica que el 45% de la población es pobre (cobra menos de $288). Dicho de otra forma P (X <288)=0.45 (si tomo un habitante de esa población, la probabilidad de que esa persona cobre menos de $288 es 0.45).
Veamos otro ejemplo de cómo usar la distribución normal.
Averigüemos el porcentaje de personas que cobran entre $288 y $305. Estaríamos buscando el área de la Figura 4.14. Si estandarizamos los valores 288 y 305 obtenemos:
\( Z=\frac{288-300}{100} = -0.12 \ \ \) y \( \ \ Z=\frac{305-300}{100}=0.05 \)
Es decir, estamos buscando el área entre \( –0.12 \) y \( 0.05 \) en la normal que está tabulada (Figura 4.15).
Tablas de distribución normal más complejas se encuentran en los libros de estadística citados en la bibliografía.
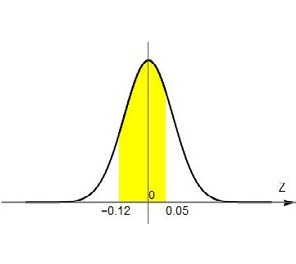
Podemos encontrar el área de la Figura 4.15 restando las áreas de las figuras 4.16. y 4.17.
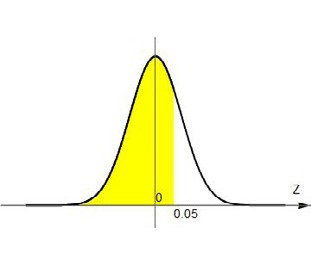
Buscamos en la tabla los valores de \( Z \) más parecidos a \( 0.05 \) y \( –0.12 \) y obtenemos las áreas correspondientes que serían 0.52 y 0.45, así que el área que buscamos es 0.52-0.45=0.07. En símbolos, P (288 <X<305)=0.07. El porcentaje de la población que cobra entre $288 y $305 es el 7%.
Preguntémonos ahora qué porcentaje cobra más de $350. Estandarizamos ese valor y obtenemos \( Z= \frac{400-350}{100} = 0.5 \); igual que antes, las áreas que buscamos son las de la Figura 4.18:
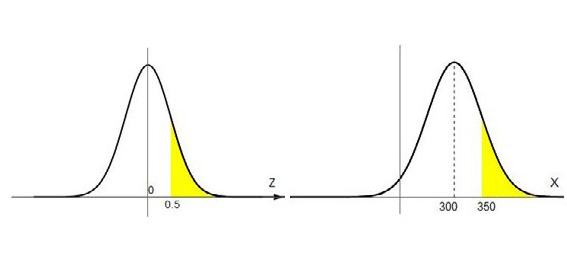
Para hallarlas hacemos lo siguiente:
Sabemos que si buscamos en la tabla el valor \( Z = 0.5 \) vamos a obtener el área desde \( 0.5 \) hacia atrás, que según la tabla es \( 0.69 \), pero si recordamos que el área total bajo la curva es 1, obtenemos fácilmente el área desde 1 hacia adelante haciendo \( 1-0.69 = 0.31 \). Luego, \( P(X>50)= 0.31 \), o, dicho de otra forma, el porcentaje de la población que cobra más de $350 es el 31%.
Hagamos una última cuenta que nos llevará a usar la tabla de otra forma. Supongamos que queremos darle un subsidio al 5% más pobre. ¿Desde qué salario para abajo se cobrará ese subsidio? El dato que tenemos aquí no es un valor de la variable X (un salario), sino un porcentaje (una probabilidad, un área) y justamente lo que queremos averiguar es un salario, un valor de la variable X.
Podemos proceder de esta forma: según la tabla, el valor de Z que tiene un área acumulada hacia atrás de 0.05 (el 5%) es Z = – 1.64 (este valor de Z lo buscamos mirando los valores de F (Z)). Ahora transformamos el valor Z al valor X mediante \( X=Z \cdot \sigma + \mu \) y obtenemos: \( X = –1.64 X 100+300=136\).
O sea que las personas que cobran $136 o menos forman el 5% más pobre de la población y cobrarán el subsidio.
Existen muchas preguntas de este estilo que podrían hacerse, pero se deja al lector indagar sobre cómo resolverlas con estas herramientas.
En síntesis, la distribución normal nos sirve para calcular probabilidades de algunos sucesos que responden a esta distribución. La campana de Gauss es la curva que nos permite visibilizar esta distribución normal. Si bien existen diferentes curvas todas ellas pueden ser traducidas a una curva estándar, conocida como desviación normal estándar. Esta no es otra cosa que una curva de distribución normal que ya ha sido estudiada y tabulada. La curva de desviación normal estándar nos permite calcular probabilidades.
Luego de ver el video responda:
- ¿Qué es la campana de Gauss?
- ¿Qué es la desviación estándar?
- ¿Cuáles son las características de la distribución normal?
Las autoridades de una ciudad intentan planificar algunos aspectos de su consumo de gas. Por estudios y registros anteriores se sabe que, en esa ciudad, el consumo anual de gas sigue una distribución normal con un promedio de 18 millones de metros cúbicos (18 Mm3) y un desvío estándar de 4 Mm3.
- ¿Cuál es la probabilidad de que el próximo año se consuman por lo menos 15 Mm3?
- ¿Cuál es la probabilidad de que el próximo año se consuman como máximo 24 Mm3?
- ¿Cuál es la probabilidad de que el próximo año se consuman entre 15 y 24 Mm3?
- Si el consumo de gas es inferior al que corresponde al 10% de los años de menor consumo, se premiará a la ciudad con una rebaja en la tarifa del gas. ¿Cuál es el máximo consumo que deberá tener la ciudad para recibir dicho premio?
Respuestas:
- 0.77(el 77%)
- 0.93 (el 93%)
- 0.70 (el 70%)
- Como máximo 12.88 Mm3
4.4. Estimación
Muchas veces un investigador se pregunta acerca del valor de algún parámetro estadístico de interés. Por ejemplo, si se estudia una población: ¿qué promedio de edad tiene?, ¿qué porcentaje de mujeres hay?, ¿qué porcentaje de mujeres pobres hay?, ¿cuál es el promedio de sus salarios? ¿cuál es la dispersión (el desvío estándar) de sus salarios?, ¿hay diferencia entre lo que el investigador esperaba y lo que observa?
El problema es que en muchos casos la población es tan grande que es muy costoso (o imposible) recabar los datos necesarios para hacer los cálculos exactos. Por ejemplo, si quiero saber qué porcentaje de niños pobres hay en una población de un millón de habitantes, debería contar todos los niños pobres de esa población y dividirlo por un millón. Contar todos los niños pobres de esa población quizás sea muy complicado y requiera de muchos recursos ¿Qué hacer entonces? Lo más lógico sería tomar una pequeña muestra de esa población y, de acuerdo con lo que ahí suceda, se puede estimar lo que pasa en la población total.
Por ejemplo, si tomo una muestra de esa población y resulta que en ella hay un 10% de niños pobres, se podría suponer que en la población total hay un 10% aproximadamente de niños que son pobres. Pero ¿qué precisiones podríamos dar acerca de esa estimación puntual?, ¿cuántas personas deberíamos muestrear para conseguir la precisión que buscamos? La estadística, en su larga historia, ha dado respuestas impactantes al respecto. En esta sección solo veremos dos de ellas: la estimación de promedios y la estimación de proporciones, cuando existe la capacidad de tomar una muestra de al menos 30 elementos de la población.
Se omite aquí la teoría del muestreo (que trata de cómo tomar una muestra para considerarla “representativa” de la población) y una infinidad de otras estimaciones posibles (como desvíos estándar, diferencias de promedios entre dos poblaciones, diferencias de propor ciones, etc.).
4.4.1. Estimación de promedios y de proporciones
En este apartado veremos un método estándar para arribar a la estimación de promedios y de proporciones. Comenzamos con la justificación matemática del método que emplearemos para la estimación; sin embargo, por más dificultosa que parezca esta explicación, la ejecución del método es muy sencilla si se aplica correctamente.
Nota: de aquí en adelante supondremos que estamos trabajando en una población “muy grande”, más de 10.000 elementos, por poner algún número de referencia.
Comenzamos dando dos resultados que se basan en un teorema célebre de la estadística: el Teorema Central del Límite.
- Primer resultado: si una población, tiene media \( \mu \) y desvío \( \sigma \), y se toman muestras de tamaño “n” de esa población, con n >30, entonces los promedios de esas muestras “\( \bar{x} \)” siguen (aproximadamente) una distribución normal con promedio \( \mu \) y desvío \( \sigma / \sqrt n \) (más allá de cómo sea la distribución de probabilidades de esa población).
- Segundo resultado: si queremos estimar una proporción p de una población y se toman muestras de tamaño “n”, con n > 30, entonces las proporciones de esas muestras “\( \hat{p} \)” siguen (aproximadamente) una distribución normal con promedio p y desvío \( \sqrt{ \frac{ \hat{p} \cdot (1-\hat{p}) }{n} } \) (más allá de cómo sea la distribución de probabilidades de esa población).
Dicho esto, veamos cómo usar estos resultados: supongamos que queremos estimar, con un 90% de confianza, el promedio de una población. Según el primer resultado, si tomo una muestra de tamaño n > 30, entonces la variable \( Z= \frac{\bar{x}- \mu}{\frac{\sigma}{\sqrt{n}}} \) sigue una distribución normal estándar, o sea con media \( \mu = 0 \) y desvío \( \sigma =1 \) (la única que está tabulada). Es fácil construir un intervalo en el cual se esté seguro de que la variable Z aparece con un cierto grado de confianza. Por ejemplo, si queremos construir un intervalo en donde la variable Z esté contenida con un 90% de probabilidad basta con buscar un valor de Z que acumule un área a su izquierda de 0.05 o de 0.95 como se muestra en la Figura 4.19. Con encontrar el extremo superior alcanza, ya que el otro extremo del intervalo es su opuesto. Llamaremos al extremo superior Zs (el extremo inferior será entonces – Zs). Si buscamos en la tabla de la distribución normal (en las columnas F(Z)) vemos que el valor de Z que deja a la izquierda 0.95 es Zs= 1.64 (véase Tabla 4.8).
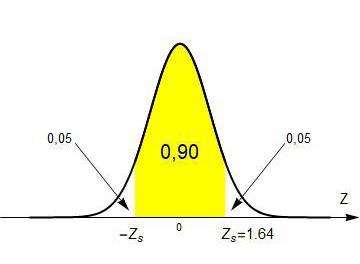
Eso quiere decir que Z se mueve entre los valores -1.64 y 1.64 con un 90% de confianza. Pero \( Z= \frac{\bar{x}- \mu}{\frac{\sigma}{\sqrt{n}}} \) así que \( \frac{\bar{x}- \mu}{\frac{\sigma}{\sqrt{n}}} \) se mueve entre esos valores con un 90% de confianza.
En símbolos \( -Z_s \leq \frac{\bar{x}- \mu}{\frac{\sigma}{\sqrt{n}}} \leq Z_s \)
Si se “despeja” el valor de \( \mu \) de esta última inecuación, se obtiene que \( \bar{x} - Z_s \cdot \frac{\sigma}{\sqrt{n}} \leq \mu \leq \bar{x} + Z_s \cdot \frac{\sigma}{\sqrt{n}} \).
O sea que el valor de la media poblacional se mueve entre los valores \( \bar{x} - Z_s \cdot \frac{\sigma}{\sqrt{n}} \) y \( \bar{x} + Z_s \cdot \frac{\sigma}{\sqrt{n}} \) con la confianza que uno desee.
En resumen, para estimar el promedio se debe aplicar la siguiente fórmula:
Si buscamos estimar la media de una población y tomamos una muestra de tamaño \( n > 30 \), y conocemos el desvío estándar de la población, entonces nuestro intervalo de confianza es \( \left[ \bar{x} - Z_s \cdot \frac{\sigma}{\sqrt{n}} \leq ; \leq \bar{x} + Z_s \cdot \frac{\sigma}{\sqrt{n}} \right] \) donde el valor \( Z_s \) depende de la confianza que elijamos.
Los valores de Zs más comunes son:
Confianza=90%----------> Zs = 1.645
Confianza=95%----------> Zs = 1.96
Confianza=99%----------> Zs = 2.575
Nota importante: si no conocemos el valor del desvío estándar de la población “\( \sigma \)”, podemos usar, en su lugar, el valor del desvío estándar de la muestra “s”, pero necesitaremos que el tamaño de la muestra sea más grande, mayor a 120. De lo contrario, habría que usar una distribución de probabilidades distinta a la normal denominada t – Student que no estudiaremos aquí. Concretamente:
Si buscamos estimar la media (promedio) de una población y tomamos una muestra de tamaño \( n > 120 \), y no conocemos el desvío estándar de la población, entonces nuestro intervalo de confianza es \( \left[ \bar{x} - Z_s \cdot \frac{s}{\sqrt{n}} \leq ; \leq \bar{x} + Z_s \cdot \frac{s}{\sqrt{n}} \right] \)
Ahora bien, si nuestra intención es estimar una proporción de una población podemos llegar a una fórmula que se obtiene a partir de una deducción similar a la de los promedios:
Si buscamos estimar una proporción (un porcentaje) de una población y tomamos una muestra de tamaño \( n > 30 \), entonces nuestro intervalo de confianza es \( \left[ \hat{p} - Z_s \cdot \sqrt{\frac{\hat{p}\cdot (1-\hat{p})}{n}} ; \hat{p} + Z_s \cdot \sqrt{\frac{\hat{p}\cdot (1-\hat{p})}{n}}\right] \)
- Para estimar un promedio conociendo el desvío estándar de la población se debe usar la siguiente fórmula: \[ \left[ \bar{x} - Z_s \cdot \frac{\sigma}{\sqrt{n}} ; x + Z_s \cdot \frac{\sigma}{\sqrt{n}} \right] \]
- Para estimar un promedio sin conocer el desvío estándar de la población se debe usar la siguiente fórmula: \[ \left[ \bar{x} - Z_s \cdot \frac{s}{\sqrt{n}} ; \bar{x} + Z_s \cdot \frac{s}{\sqrt{n}} \right] \]
- Para estimar una proporción la fórmula a usar es la siguiente: \[ \left[ \hat{p} - Z_s \cdot \sqrt{\frac{\hat{p}\cdot (1-\hat{p})}{n}} ; \hat{p} + Z_s \cdot \sqrt{\frac{\hat{p}\cdot (1-\hat{p})}{n}} \right] \]
A continuación, presentamos tres ejemplos de aplicación de la estimación de promedios y proporciones:
Ejemplo 1
Queremos estimar, en una población muy grande, el promedio de los salarios de sus habitantes. Se sabe por estudios anteriores que el desvío estándar de los salarios de la población es de $1300. Se toma una muestra de 50 individuos de esa población y se obtiene un promedio (en esa muestra) de $18000.
Construiremos un intervalo de 95% de confianza para el salario promedio de toda la población:
Datos:
Tamaño de la muestra \( n=50 \); desvío de la población \( \sigma = 1300 \).
Promedio de la muestra \( \bar{x} = 18000 \); confianza 95% ----> \( Z_s = 1.96 \)
Entonces el intervalo buscado es:
\[ \left[ 18000 - 1.96 \times \frac{1300}{\sqrt{50}} ; 18000 + 1.96 \times \frac{1300}{\sqrt{50}} \right] = \left[ 17639.7 ; 18360.3 \right] \]
El salario promedio de toda la población está entre $17639.7 y $18360.3 con un 95% de confianza.
Ejemplo 2
Se quiere estimar, en una ciudad muy grande, el promedio de metros cuadrados destinados a espacios verdes cada 10.000 \( m^2 \). Se toman 150 espacios de 10.000 \( m^2 \) cada uno y se mide cuántos metros cuadrados de espacios verdes hay en cada uno de ellos. Se obtiene, en esos 150 espacios estudiados, un promedio de 500 \( m^2 \) de espacios verdes y un desvío estándar de 100 \( m^2 \). Se busca una confianza del 99%.
Datos:
Tamaño de la muestra \( n = 150 \); desvío de la muestra \( s=100 \)
Promedio de la muestra \( \bar{x}= 500 \); confianza 99% ----> \( Z_s = 2.575 \)
Entonces el intervalo buscado es:
\[ \left[ 500 - 2.575 \times \frac{100}{\sqrt{150}} ; 500 + 2.575 \times \frac{100}{\sqrt{150}} \right] = \left[ 479; 521 \right] \]
En esa ciudad, el promedio de espacios verdes cada 10.000 \( m^2 \) está entre 479 \( m^2 \) y 521 m2 con un 99% de confianza.
Ejemplo 3
Se quiere estimar en una gran ciudad, el porcentaje “p” de mujeres que han sufrido algún tipo de acoso en el último año. Se encuesta a 250 mujeres de las cuales 150 manifiestan que han sufrido algún tipo de acoso en el último año. Estimar “p” con un intervalo del 90% de confianza.
Datos:
Tamaño de la muestra \( n = 250 \) ; confianza 90% ----> \( Z_s = 1.645 \);
Porcentaje de la muestra \( \hat{p} = \frac{150}{250} = 0.6 \text{ (el 60%)} \)
Entonces el intervalo buscado es: \[ \left[ 0.6 - 1.645 \cdot \sqrt{\frac{0.6 \times (1-0.6)}{250}} ; 0.6 + 1.645 \cdot \sqrt{\frac{0.6 \times (1-0.6)}{250}} \right] = \left[ 0.549; 0650 \right] \]
Concluimos que, en esa ciudad, el porcentaje de mujeres que han sufrido algún tipo de acoso en el último año está entre el 54,9 y el 65% con un 99% de confianza.
4.4.2. Tamaño de la muestra
Intuitivamente, se supondría que cuantos más elementos se hayan tomado en la muestra, mayor será la precisión en la estimación, es decir, la longitud del intervalo de confianza obtenido será menor. No lo haremos aquí, pero analizando las fórmulas de los intervalos se corrobora fácilmente esta suposición: a mayor tamaño de la muestra se obtiene una longitud menor en el intervalo de confianza (se disminuye el error en la estimación). Además, haciendo unas simples cuentas y unas mínimas aproximaciones se puede determinar el tamaño de la muestra “μ” necesario para obtener una determinada longitud “L” del intervalo de confianza buscado.
En las situaciones que estamos viendo se obtiene:
- Si estimamos la media “\( \mu \)” y queremos que la longitud del intervalo no supere el valor “L”, entonces el tamaño de la muestra debe ser de por lo menos \( n = \left( \frac{2 \cdot Z_s \cdot \sigma}{L} \right)^2 \) o \( \left( \frac{2 \cdot Z_s \cdot s}{L} \right)^2 \) (dependiendo si se conoce el valor del desvío estandar de la población \( \sigma \) o solo se conoce el valor del desvío estándar de la muestra s).
- Si estimamos una proporción “p” y queremos que la longitud del intervalo no supere el valor “L”, entonces el tamaño de la muestra debe ser de por lo menos \( n = \left( \frac{Z_s}{L} \right)^2 \).
Ejemplo
Cuando estimamos en el ejemplo anterior el porcentaje “p” de mujeres que han sufrido algún tipo de acoso en el último año, obtuvimos el intervalo [0.549 ; 0.650] (entre el 54,9% y el 65% de las mujeres). La longitud de ese intervalo es de 0.101 (que resulta de restar el extremo superior 0.650 menos el inferior 0.549). Eso corresponde (porque estamos hablando de porcentajes) a una longitud del 10,1% que podría ser considerada como una longitud excesiva. Decir que el porcentaje de mujeres que han sufrido algún tipo de acoso es algún número que está dentro de un intervalo de longitud 0.101 (o el 10.1%) es muy poco preciso. Supongamos que quisiéramos que esa longitud no fuera superior al 4% (o sea una longitud de 0.04), ¿cuál debería ser el tamaño de la muestra para garantizar esa longitud, esa precisión? Según la fórmula anterior:
\[ n = \left( \frac{Z_s}{L} \right)^2 = \left( \frac{1.645}{0.04} \right)^2 \cong 1692 \]
Es decir, que deberíamos encuestar por lo menos a 1692 mujeres para obtener un intervalo para p de una longitud no mayor del 4%.
En este punto, estamos en condiciones de realizar el último ejercicio de la unidad. Tenga presente que necesita haber resuelto los anteriores.
Los datos del ejercicio 1 constituyen una muestra de 121 pacientes de la población de enfermos de covid hasta el 21/09/2020 en Argentina. Esa población es muy grande (623.142 enfermos) y con los datos de la muestra se intentará estimar algunos parámetros de la población total (enfermos de covid hasta el 21/09/2020 en Argentina).
- Estimar con un 95% de confianza el promedio de edad de la población de enfermos de covid hasta el 21/09/2020 en Argentina.
- Estimar con un 90% de confianza la proporción de pacientes que tuvieron que ser internados de la población de enfermos de covid hasta el 21/09/2020 en Argentina.
- ¿Qué tamaño debería tener la muestra si quisiéramos que el intervalo de confianza anterior tuviera una longitud total de 0,06 (un 6%)?
(Respuesta en el anexo)
El siguiente video muestra el circuito de la estadística descriptiva: a partir de una población se toma una muestra, se sacan los datos y se analiza esta muestra. Con dichos resultados se puede estimar qué es lo que sucede en la población.
Somos conscientes de las dificultades que acarrea la estadística en la formación de los geógrafos, pues sabemos que hay cierta reticencia a los trabajos neopositivistas y a la matemática. Sin embargo, un análisis territorial no debería dejar de lado herramientas como la estadística descriptiva, la probabilidad y la estimación, ya que nos permiten ordenar los datos y arribar a conclusiones a las que no podríamos llegar si contamos con la información ordenada de otra manera (o desordenada).
Por ejemplo, si estamos analizando los medios de transporte que se utilizan en la ciudad de Paraná (auto, bicicleta, moto, transporte público) y realizamos una encuesta a los habitantes y le preguntamos cómo se desplaza y en qué lugar de la ciudad vive, la estadística nos permitirá sacar porcentajes y/o estimaciones sobre cuál es el medio elegido por los paranaenses para transitar la ciudad. Además, si sabemos el barrio, podemos agruparlos por unidades espaciales y graficarlos en un mapa. (Recuerde lo visto en Introducción a la Semiótica Cartográfica y SIG).
En fin, el objetivo de esta unidad es restar el prejuicio que habitualmente se tiene sobre el manejo de datos estadísticos y sortear el obstáculo epistemológico en que se convierten, generalmente, los libros de estadísticas. Esperamos haber proporcionado elementos que sirvan para analizar los problemas socioespaciales.