3. La herramienta de la teledetección: el análisis visual y el procesamiento de imágenes
Objetivos de la Unidad
- Acercar a las y los estudiantes al análisis visual de la fotointerpretación clásica.
- Aproximar a las y los estudiantes al tratamiento digital básico de la imagen.
- Comprender las ventajas y limitaciones del análisis visual y el tratamiento de imágenes.
3.1. La extracción de información de las imágenes
En general, la extracción de información de las imágenes de teledetección puede clasificarse en dos grupos: la extracción de información basada en la interpretación de imágenes visuales (métodos de interpretación visual para el uso del suelo, vegetación, etc.) (imagen 87), o la extracción de información a través del procesamiento semiautomático de programas informáticos mediante una computadora (generación automática de DTM, clasificación de imágenes digitales, etc.) (imagen 88). Es necesario señalar que hablamos de dos métodos complementarios, no opuestos ni excluyentes (Chuvieco, 2002).
Mapa de rodales (cobertura vegetal) resultado de la interpretación visual sobre ambos materiales
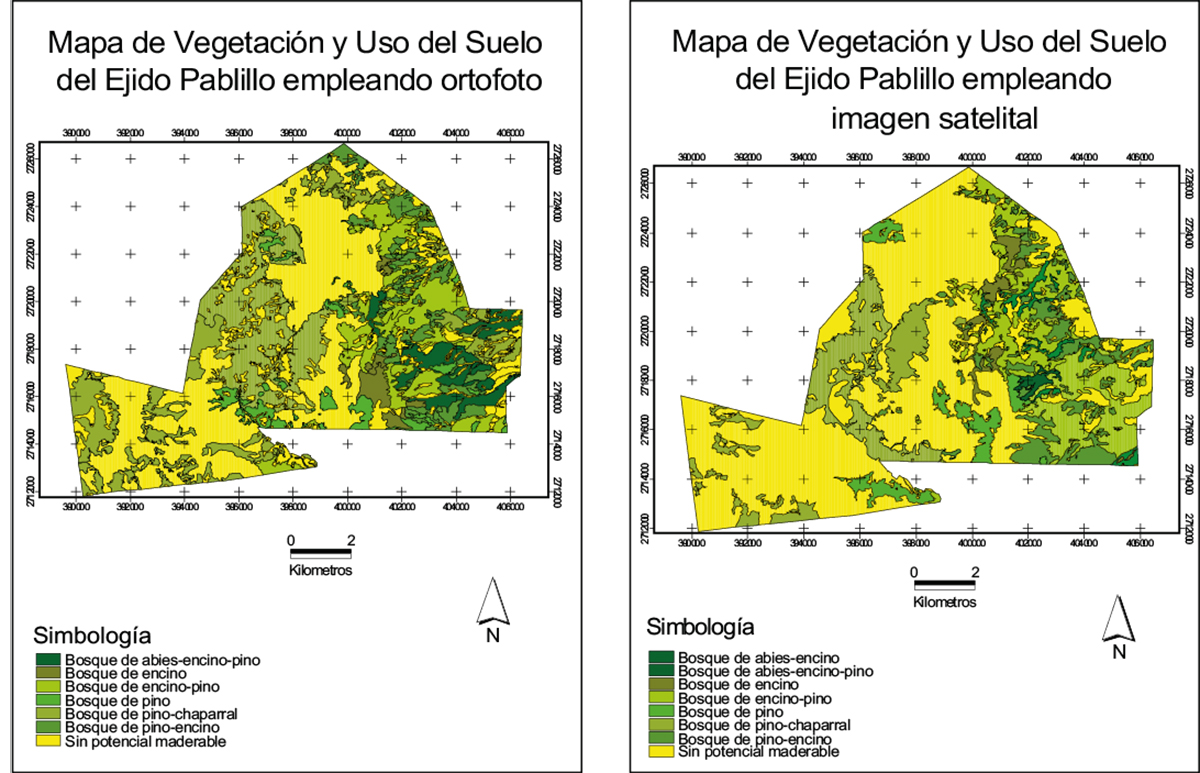
Fuente: Ancira-Sánchez y Treviño Garza, 2015.
MDT (Modelo Digital del Terreno) y MDS (Modelo Digital de Superficie) bosque
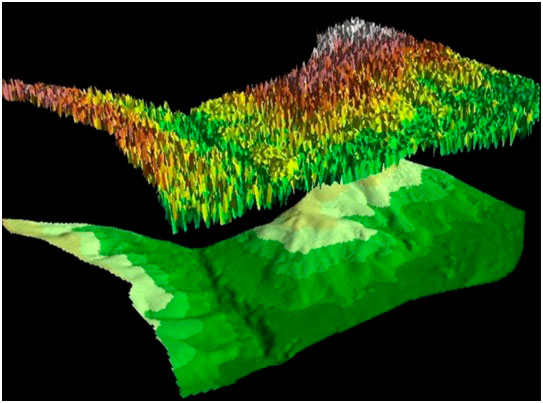
Fuente: <https://www.cursosteledeteccion.com/>
La forma más intuitiva de extraer información de imágenes de sensores remotos es mediante la interpretación visual de imágenes, que se basa en nuestra capacidad para relacionar las características de una imagen (color, tono, sombras, etc.) con las características que percibimos en el mundo real. Cuando identificamos lo que vemos en imágenes de satélite y fotografías aéreas, y transmitimos esa información, estamos realizando fotointerpretación. Hay varias formas de transmitir la información; la manera más utilizada y más útil suele ser la generación de cartografía (mapas). Hasta no hace mucho tiempo, la práctica requería superponer una transparencia sobre una fotografía y delinear las características de interés que reconocíamos en un área concreta. Al hacer este ejercicio para todas las características de interés que observábamos en dicha área, obteníamos un mapa. La variante digital de este enfoque es digitalizar la imagen, ya sea en pantalla o utilizando una tableta digitalizadora; de esta manera podemos obtener, por ejemplo, un mapa de todas las parcelas dedicadas a la viticultura en un área determinada y rutas y autopistas que llevan a ellas. Una particularidad de la interpretación de la imagen es que podemos utilizar varias imágenes superpuestas (visión estereoscópica) con el mismo proceso interpretativo (aunque con la ayuda de aparatos específicos) (imagen 89) (Chuvieco, 1995).
Estereoscopio para información visual tridimensional de la imagen

La interpretación de la imagen visual no es tan fácil como puede parecer a priori, requiere entrenamiento. No obstante, nuestro sistema ojo-cerebro es capaz de hacer este ejercicio interpretativo. Esta interpretación visual es, de hecho, un proceso extremadamente complejo cuya finalidad es reconocer características y objetos en imágenes. La interpretación de la imagen visual se utiliza para producir datos geoespaciales en muchos campos de aplicación: cartografía urbana, usos del suelos, geomorfológía, oceanografía, defensa, catástrofes naurales (imagen 90), etc. (CONAE, 2016).
Área de inundación delimitada siguiendo la curva 2210 metros. Caso de estudio: río Soapaga, sector Paz deRío, Boyacá
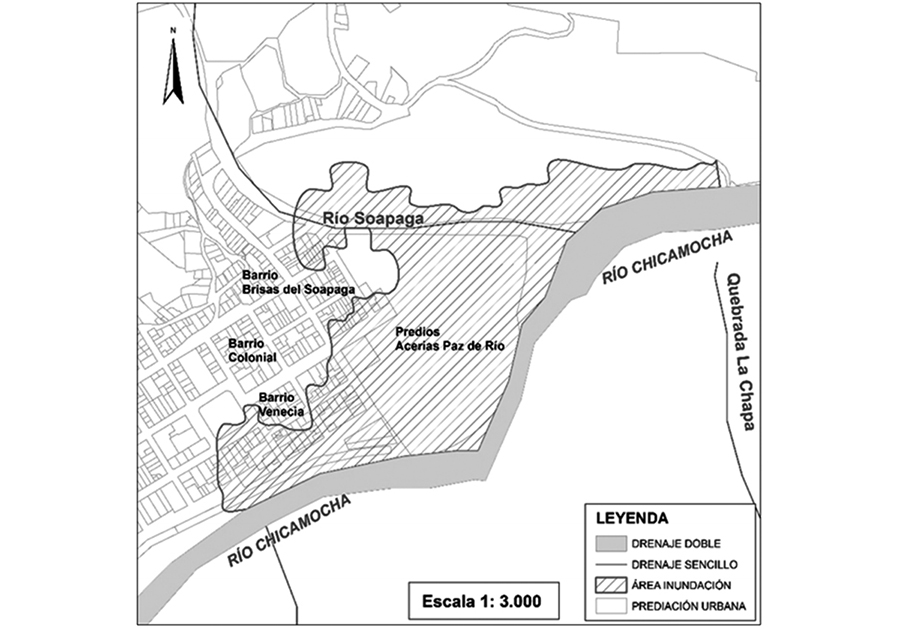
En una imagen de satélite (también en fotografías aéreas) pueden observarse varios objetos de diferentes tamaños y formas, algunos de ellos se identifican claramente y de manera correcta mientras que otros no, dependiendo de las percepciones individuales y de la experiencia del intérprete. De este modo, el o la intérprete puede encontrarse ante dos situaciones: la primera, un reconocimiento directo y espontáneo de un objeto o fenómeno (porque es conocido por el intérprete), y la segunda, la necesidad de realizar un ejercicio de razonamiento en el que se utiliza el conocimiento profesional y la experiencia para identificar un objeto en la imagen (inferencia lógica). En ocasiones, este razonamiento será insuficiente, teniendo que apoyarse, para la interpretación correcta, en el trabajo de campo. El trabajo de la persona que interpreta consiste en examinar cada elemento de la imagen de tres formas: individualmente, en relación con otro elemento presente y, finalmente, en relación con todo el patrón de la imagen (imagen 91). La correcta interpretación visual va a depender de tres factores fundamentalmente: primero, de la experiencia y el entrenamiento de la persona que interpreta (por ejemplo, una ingeniera agrónoma reconocería de inmediato los sistemas de riego de pivote por su forma circular,podría identificarlo por una experiencia (profesional) anterior; segundo, de la naturaleza del fenómeno que se estudia (no es lo mismo estudiar coberturas vegetales terrestres que vegetación en el fondo de los océanos) y, finalmente, la calidad de la imagen que se va a interpretar (CONAE, 2016; Tempfli, Kerle, Huurneman y Jansse, 2009).
Laboratorio de teledetección

Los datos digitales y el procesamiento de imágenes requieren el uso de computadoras para manejar metódicamente los valores brutos adquiridos por los sensores, produciendo datos y luego imágenes que aporten información útil. Normalmente, existe una amplia variedad de productos para el tratamiento de datos e imágenes de cualquier sensor. Gran parte del procesamiento de datos requiere un conocimiento detallado de las características, las especificaciones técnicas y los sistemas de registro de datos de un sensor. El desarrollo de software, el procesamiento operativo y el control de calidad pueden ser costosos y llevar mucho tiempo (CCPO, 2003).
El procesamiento inicial (a veces denominado preprocesamiento) a menudo es parcial, si no completamente, realizado por la entidad que proporciona las imágenes del sensor. Este paso convierte los valores en bruto en un formato más útil. Los números reformateados luego suelen someterse a algún tipo de tratamiento de "calibración", que ajusta la respuesta medida de un sensor a los valores absolutos de intensidad de iluminación. Las correcciones geométricas que minimizan las distorsiones espaciales también se pueden hacer antes de distribuir datos de imagen. Un procesamiento más avanzado puede corregir datos de sensores remotos para los efectos de la atmósfera. Los efectos atmosféricos son complejos, y la extensión de los efectos depende de las condiciones atmosféricas, la longitud de onda espectral, la altura del sensor sobre el nivel del suelo y otros factores. Otras técnicas avanzadas de procesamiento pueden ajustar los datos de detección remota para las variaciones causadas por diferentes ángulos de sol y las condiciones de ángulo de visión. La altura del Sol en el cielo y el ángulo en el que un sensor “observa” una superficie influyen en el brillo detectado (CONAE, 2016; Tempfli, Kerle, Huurneman y Jansse, 2009).
Los tipos de procesamiento a los que se ha sometido un conjunto de datos (que pueden incluir algunos o quizás todos los anteriores), están normalmente indicados por varias categorías de "nivel" de producto. La información sobre los niveles se puede obtener de un proveedor de datos. El procesamiento de rutina generalmente lo realiza un proveedor de datos; el procesamiento avanzado puede ser realizado por un proveedor o por investigadores/as si tienen los medios. Las y los usuarios deben conocer los productos de datos que requieren para su trabajo en particular.
Hay muchas formas de manipular digitalmente datos e imágenes. La mejora de la imagen se utiliza para facilitar la interpretación visual. Usando una serie de técnicas especiales, se pueden mejorar las imágenes para mejorar la identificación de las características que son de interés. La clasificación de imágenes utiliza técnicas cuantitativas para identificar y subdividir los píxeles de la imagen en clases. Una variedad de criterios de decisión basados en estadísticas y rutinas de reconocimiento de características espectrales (en menor medida espaciales y temporales) ayudan a determinar el tipo de cubierta de cada píxel. Hay dos tipos generales de clasificación de imágenes: supervisadas (los descriptores numéricos de las clases de cobertura terrestre deseadas se especifican para el programa de clasificación) y no supervisadas (el programa de clasificación subdivide los píxeles en agrupaciones naturales o agrupaciones sin ninguna especificación a priori).
La fusión de datos y su integración en SIG (sistemas de información geográfica) combinan datos de imagen para áreas geográficas particulares con otros conjuntos de datos geográficamente referenciados para la misma área, ampliando el abanico de posibilidades de análisis y obtención de información (CCPO, 2003).
Teledetección: Observar la Tierra desde el espacio
Fuente: Magellan Aerospace Industries. Disponible en: <https://www.youtube.com/watch?v=R6ZFXJ_auH4> [Consulta: 18 de octubre 2014].
Comisión Nacional de Actividades Espaciales (CONAE) (2016), “Guía de Interpretación Visual de Imágenes Satelitales”. Programa Educativo 2Mp. Buenos Aires, CONAE, pp. 1-11. Disponible en <https://2mp.conae.gov.ar/descargas/Documentos/Guia_de_interpretacion_visual_de_imagenes_satelitales.pdf>
Reflexione y conteste las siguientes preguntas:
- ¿Cuál es la relación entre visualización de datos e interpretación de imágenes?
- ¿Cuál sería un método relativamente simple para verificar la calidad de interpretación de la imagen visual?
- ¿Qué productos de su entorno profesional se basan en la interpretación de imágenes visuales?
- ¿Cuáles son las razones principales para realizar observaciones de campo en el proceso de interpretación de imágenes?
3.2. Análisis visual clásico
Como se señaló anteriormente, el “ojo-cerebro” humano posee la capacidad de sacar conclusiones a partir de observaciones visuales. Al analizar una imagen, normalmente se encuentra en algún lugar entre las dos situaciones siguientes: “directo y reconocimiento espontáneo” o “utilización de pistas para extraer conclusiones mediante un proceso de razonamiento”. Las imágenes de satélite y las fotografías aéreas se diferencian de otro tipo de imágenes principalmente porque: a) muestran datos desde una perspectiva elevada, lejana y, a menudo, no familiar; b) suelen usarse longitudes de onda que no están en el espacio visible del espectro electromagnético; y c) utilizan escalas y resoluciones no habituales. Estas diferencias pueden dificultar su interpretación, especialmente en un análisis inexperto. Para ayudar en el estudio de la imagen existe una serie de características específicas básicas (convenciones tras un estudio sistemático de las imágenes) para su interpretación. Estas características básicas también son consideradas por las aplicaciones digitales (CONAE, 2016; Tempfli, Kerle, Huurneman y Jansse, 2009).
La metodología utilizada en la interpretación visual de imágenes engloba las siguientes etapas: 1) delimitar el objetivo del trabajo y establecer los objetivos que se pretende alcanzar; 2) definir el área de estudio; 3) seleccionar el material necesario (para las imágenes es necesario tener en cuenta elementos como la fecha, bandas, etc.); 4) búsqueda de información complementaria; 5) bibliografía específica; 6) delimitar clases o categorías (unidades homogéneas); 7) corresponder cada unidad homogénea (clase o categoría) con un símbolo para generar una leyenda; 8) comprobación mediante salida a campo (control terrestre); y 9) elaboración de cartografía interpretativa final.
Tempfli, K., Kerle, N., Huurneman, G., y Jansse, L. (eds.) (2009). Principles of Remote Sensing. An introductory text book, Enschede, ITC, pp. 170-179 y 255-265. Disponible en <https://webapps.itc.utwente.nl/librarywww/papers_2009/general/principlesremotesensing.pdf>
3.2.1. Criterios visuales para la identificación
Como se viene señalando, necesitamos una serie de criterios para expresar las características de una imagen a la hora de interpretarla. Cada critero incluye una serie de elementos de interpretación para su operacionalidad. Según el grado de complejidad de los criterios, los elementos de interpretación pueden agruparse jerárquicamente en criterio espectral (tono y color), criterio espacial simple (textura, tamaño y forma), criterio espacial complejo (sombras, localización, patrón especial) y criterio temporal (condiciones estacionales) (imagen 92) (Chuvieco, 2002).
Chuvieco, E. (1995). Fundamentos de Teledetección Espacial. Madrid, Rialp, S.A. Capítulo 5. Disponible en <https://pdfhumanidades.com/sites/default/files/apuntes/FUNDAMENTOS-DE-TELEDETECCION-EMILIO-CHUVIECO.pdf>
Factores que influyen en la fotointerpretación visual de una imagen
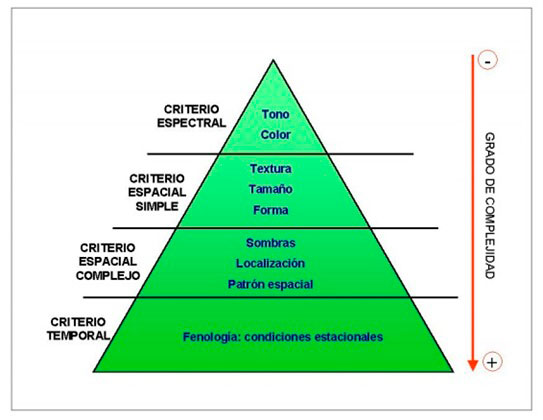
Criterio espectral
Tono
El tono se define como el brillo relativo de los objetos en una imagen en blanco y negro. Las variaciones tonales son una característica específica muy importante en la interpretación, conformándose como uno de los principales criterios de interpretación visual. El tono se refiere al color tal como se define en el espacio de color IHS (intensidad, matiz, saturación). La expresión tonal de los objetos en la imagen está directamente relacionada con la cantidad de luz (u otras formas de energía EM) reflejada (o emitida) desde la superficie. Es probable que los diferentes tipos de roca, suelo o vegetación tengan diferentes tonos. Asimismo, las variaciones en las condiciones de humedad también se reflejan como diferencias tonales en la imagen (por ejemplo, el aumento del contenido de humedad genera tonos de gris más oscuros). Las variaciones en el tono se relacionan principalmente con las características espectrales del terreno de la imagen y también con las bandas seleccionadas para la visualización. Estas diferencias pueden ser producidas por: la impresión de la imagen (distintas impresiones pueden dar distintos tonos en dos imágenes contiguas), la posición del Sol (su elevación dependiendo de la hora del día y de la estación del año), la distinta reflectividad de los elementos según la longitud de onda considerada (el tono característico de una cubierta varía con la banda del espectroN utilizada) (imagen 93) (CONAE, 2016; Tempfli, Kerle, Huurneman y Jansse, 2009).
Por ejemplo, la cobertura vegetal muestra una tonalidad más oscura en las bandas correspondientes a longitudes de onda del espectro visible, mientras que en longitudes de onda del espectro infrarrojo muestra una tonalidad más clara.
Bandas espectrales correspondiente al verde, rojo, infrarrojo cercano e infrarrojo medio

Fuente: Antes (2002)
Color
El color es una característica de luz determinada por la composición espectral de la luz en su interacción con el ojo humano. De ello se deriva que el color es un fenómeno psicofísico, y la percepción del color es subjetiva. Experimentamos la luz de diferentes longitudes de onda como diferentes colores. El ojo actúa muy similar a una cámara, con los lentes (a través de detectores de luz llamados bastones y conosN) formando la imagen de la escena en la retina, sensible a la luz (imagen 94). Los conos están agrupados en tres tipos, cada uno responde a una parte del espectro visible, con respuestas pico según la luz azul, verde y roja correspondiente. La interacción de estos elementos responde a estímulos que son interpretados por el cerebro como color (Tempfli, Kerle, Huurneman y Jansse, 2009).
Además de los conos, tenemos varillas, que perciben el brillo. Las varillas pueden operar con menos luz que los conos y no contribuyen a la visión del color. Por esta razón, los objetos aparecen menos coloridos en condiciones de poca luz.
El ojo humano. Elementos para la detección y clasificación de los colores
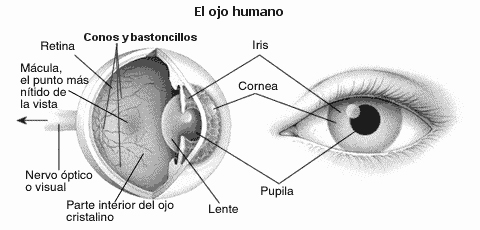
La teoría aceptada sobre la visión del color es conocida como teoría tricromática. El conocimiento del fenómeno de los “valores triestímulos” condujo al desarrollo de monitores de color. Las pantallas de televisión en color y los monitores de computadora se componen de una gran cantidad de pequeños puntos dispuestos en un patrón regular de grupos de tres: un punto rojo, uno verde y uno azul. A una distancia de visualización normal de la pantalla, no podemos distinguir los puntos individuales. Las pistolas electrónicas para rojo, verde y azul se colocan en la parte posterior del tubo de rayos catódicos. El número de electrones que disparan los monitores de color de estas pistolas en una determinada posición de la pantalla determina la cantidad de luz (roja, verde y azul) emitida desde esa posición. Por lo tanto, todos los colores visibles en dicha pantalla se crean mezclando diferentes cantidades de rojo, verde y azul. Esta mezcla tiene lugar en nuestro cerebro (imagen 95) (Tempfli, Kerle, Huurneman y Jansse, 2009).
Rango visible del espectro electromagnético, incluyendo las curvas de sensibilidad de los conos en el ojo humano
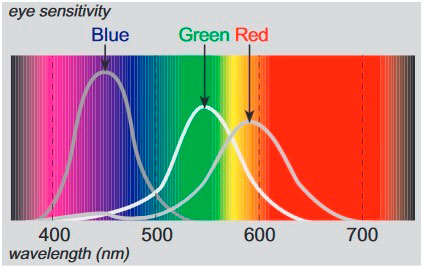
Fuente: Tempfli, Kerle, Huurneman y Jansse, 2009.
Desde el modelo triestímulo de la percepción del color (generalmente aceptado) se utilizan varios espacios tridimensionales para describir y definir los colores (imágenes 96 y 97). Los más utilizados para la interpretación de imágenes son los siguientes:
- Espacio rojo-verde-azul (RGB), que se basa en el principio aditivo de los colores.
- Espacio de intensidad-matiz-saturación (IHS), que se adapta mejor a nuestra percepción intuitiva del color.
- Espacio amarillo-magenta-cian (YMC), que se basa en el principio sustractivo de los colores. (Tempfli, Kerle, Huurneman y Jansse, 2009: 173)
Combinaciones de bandas Landsat 8 (Dublín, Irlanda)
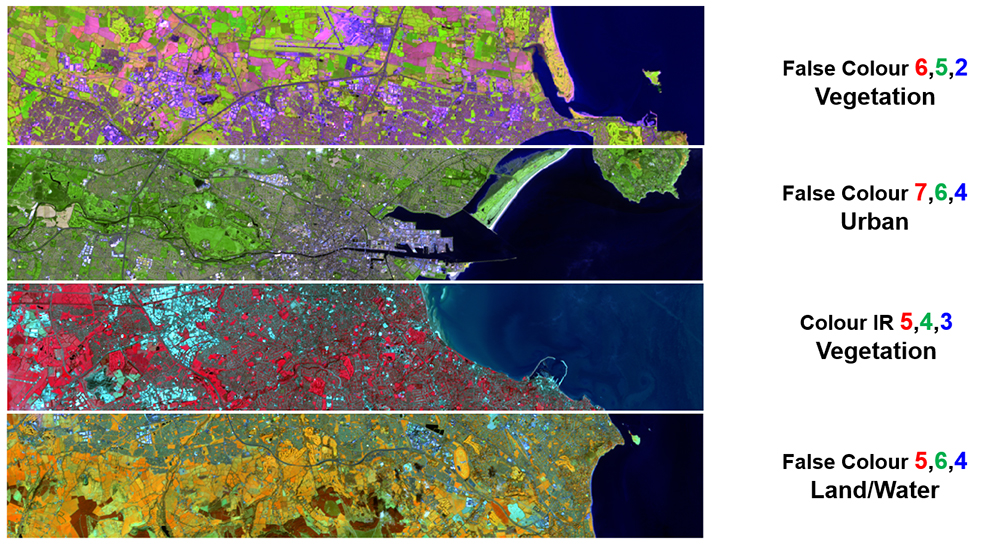
Combinación RGB 562 de bandas Landsat para análisis de vegetación y cultivos

La ventaja del color sobre el tono es que el ojo humano tiene una sensibilidad mucho mayor para las variaciones de color (aproximadamente 10.000 colores) que para el tono (aproximadamente 200 niveles de grises) (Chuvieco, 1995).
Criterio espacial simple
Textura
La textura se refiere a la frecuencia con la que suceden contrastes tonales (píxeles) entre los elementos que componen las diferentes cubiertas. Es un criterio que aporta información sobre la heterogeneidad espacial. Esta característica se produce por una agregación de rasgos unitarios que pueden resultar indistinguibles de forma aislada, pero que, en conjunto, se diferencian respecto al resto de la foto (por ejemplo, cada parcela cultivada tiene su propia forma, tamaño, patrón, sombra y tono, pero todas estas características juntas producen una sensación visual que permite diferenciar entre un tipo de cultivo y otros). Esta valoración se refiere a la frecuencia de cambio tonal entre los píxeles. De este modo, cuanto más parecido sea el tono entre los píxeles adyacentes en la imagen, la cubierta tenderá a visualizarse con un textura más fina (lisa), mientras que si se da frecuencia alta de cambio entre estos píxeles, se conformarán texturas rugosas (gruesas). La textura es un criterio muy dependiente de la resolución espacial del sensor, las condiciones de luminosidad cuando fue tomada la imagen y la longitud de onda en la que fue registrada. Es importante prestar especial atención a estos factores ya que pueden llevar a errores en la clasificación (imagen 98) (CONAE, 2016; Tempfli, Kerle, Huurneman y Jansse, 2009).

- Cultivos (textura lisa) y selva (textura gruesa/rugosa) en Tucumán
- Localidad de Obligado, Buenos Aires (textura gruesa/rugosa)
- Ciudad de Corrientes (textura gruesa/rugosa)
- Desierto Rub al- Jali (textura lisa, excepto dunas, textura gruesa/rugosa;
- Glaciar Upsala, Santa Cruz (textura lisa);
- Valle del Cura, San Juan (textura gruesa/rugosa).
Forma
Es un criterio muy determinado por la resolución espacial de las imágenes. Hace referencia a la forma que tienen los objetos, al contorno de su perímetro o perfil, es decir, a cómo se ve en una foto bidimensional (imágenes 100 y 101). La altura/elevaciónN es un criterio a tener en cuenta, dentro de la forma, cuando se trabaja con visión estereoscópica en la interpretación visual (imagen 99).
Las diferencias de altura son importantes para distinguir entre distintos tipos de vegetación, tipos de edificios, etc. Las diferencias de elevación nos proporcionan señales en el mapeo geomorfológico. Es necesaria una visión estereoscópica para observar la altura y la elevación. La visualización estereoscópica facilita la interpretación de las características naturales y artificiales.
Superposición de imágenes para visión estereoscópica

La interpretación de las formas presta especial atención a la geometría (lineal, irregular, regular, anguloso, redondeado, etc.) y a la nitidez de los contornos (nítido, difuso, continuo, discontinuo, etc.). Es uno de los criterios más sencillos y claros. En algunos casos esta característica bastará para diferenciar el objeto de estudio de los del resto de la imagen (IGN, 2011).
Forma lineal de las pistas de aviación

Fuente: Antes, 2002
Forma irregular de los cuerpos de agua

Fuente: Antes, 2002
Tamaño
Al igual que la forma, el tamaño es un criterio muy condicionado por la resolución espacial de las imágenes. Este criterio permite comparar la dimensión de los objetos, ejercicio imprescindible para realizar una clasificación correcta. También permite establecer el tamaño más frecuente para una categoría, facilitando su fotointerpretabilidad (imagen 102). El tamaño de los objetos se puede considerar en un sentido relativo o absoluto. El ancho de una carretera se puede estimar, por ejemplo, comparándolo con el tamaño de los autos, dato generalmente conocido. Asimismo, es necesario determinar el tipo de camino según su anchura, jerarquizándolo como camino principal, camino secundario, etcétera.
La combinación de los criterios de forma y tamaño permite diferenciar cubiertas o usos que presenten comportamientos espectrales similares o idénticos (IGN, 2011).
Tamaño de lotes agrícolas y frutihortícolas (más grandes y más pequeños respectivamente)

Fuente: Antes, 2002
Criterio espacial complejo
Sombras
Las condiciones de iluminación de la superficie terrestre influyen notoriamente en la señal de radiancia recibida por el sensor y, por tanto, en los criterios visuales que se apoyan en la presencia de sombras. Es necesario prestar especial atención a la ubicación de las sombras para no introducir límites falsos en la delineación de las categorías de los objetos de la imagen. Facilita el cálculo de la altura, ayuda a la percepción tridimensional de los objetos (profundidad) y realza los rasgos geomorfológicos y texturales de la imagen, especialmente en coberturas vegetales (imagen 103). Es un criterio dependiente de la fecha de adquisición de la imagen y del relieve local (CONAE, 2016; IGN, 2011).

- Selva en Tucumán
- Valle del Cura, San Juan
- Volcán Peteroa, Chile
Localización
La localización o contexto espacial es un criterio fundamental para clasificar correctamente cubiertas que presentan una respuesta espectral muy parecida. Hace referencia a la relación de vecindad entre cubiertas, es decir, a la posición topográfica o geográfica en la que se encuentra un objeto o elemento respecto a un contexto de referencia (montaña, valle, ciudad, etc.) (imagen 104). Por ejemplo, un bosque de montañas es diferente de un bosque cerca del mar o de un bosque de ribera en un valle. Asimismo, es probable que un edificio grande al final de varios ferrocarriles convergentes sea una estación ferroviaria, no un hospital (Tempfli, Kerle, Huurneman y Jansse, 2009).
Patrón
El patrón se refiere a la disposición espacial de los objetos e implica la repetición característica de ciertas formas o relaciones. Puede describir repeticiones concéntricas, radiales, etc. (imagen 105). Por ejemplo, algunos usos de la tierra tienen patrones específicos y característicos cuando se observan desde el aire o el espacio (cultivos en aterrazamientos o bancales). La distribución regular de los olivos o vides en un olivar o viñedo, en contraste con la distribución irregular (sin patrón distinguible) de las diversas especies en una dehesa, o el sistema hidrológico (río con sus ramales) y los patrones relacionados con la erosión son otros ejemplos de patrón (CONAE, 2016; Tempfli, Kerle, Huurneman y Jansse, 2009).

- Tramas urbanas: Foz de Iguazú y Puerto Iguazú
- Lotes de cultivo, noroeste argentino
- Trama urbana: ciudad de Corrientes
- Extracción de hidrocarburos en Neuquén
- Círculos de riego, San Luis
- Deforestación en el Amazonas
- Extracción de hidrocarburos en Neuquén
Criterio temporal
Condiciones estacionales
Los aspectos temporales asociados con los fenómenos climatológicos posibilitan observar cambios en algunos de los criterios visuales expuestos anteriormente (por ejemplo, el contenido de humedad del suelo varía según la época del año). La comparación entre imágenes multianuales o multiestacionales para una misma cubierta permite distinguir estas características (imagen 106). Este tipo de análisis es muy ventajoso en cubiertas agrícolas y forestales. Las principales diferencias se van a observar en el brillo, color, sombras, geometría y patrón espacial. Por otro lado, estos aspectos son importantes para interpretar los cambios ocurridos en un período de tiempo determinado en cuanto a la acción antrópica sobre el medio (usos de suelo, deforestación, etc.) (CONAE, 2016; IGN, 2011).
El uso simultáneo de estos criterios constituye la importancia de la interpretación visual de las imágenes. En la clasificación digital de las mismas solo se analiza la respuesta espectral, hecho que revela la limitación actual de los métodos automatizados en comparación con la interpretación visual.

- Represa Urugua-í, 1986-2015
- Glaciar Upsala, 1986-2001
- Salar del Hombre Muerto, 1990-2014
- Ciudad de La Punta, 1999-2015
- Mina Bajo de la Alumbrera, 1995-2015
- Deforestación en el Amazonas 1976-2001
García-Meléndez, E. (2007), “Análisis visual de imágenes”, EOI, Universidad de León, León, pp. 1-15.
Reflexione y conteste las siguientes preguntas:
- ¿Cómo son los valores de energía reflejada del agua? Con base en su respuesta, ¿cuál debería ser la resolución radiométrica de un sistema para monitorear calidad de agua? ¿En qué zona del espectro em deberían estar las bandas?
- Por ejemplo, si el objetivo del análisis es determinar clorofila, ¿dónde deberían estar situadas las bandas? Según su respuesta, ¿se podría determinar clorofila a través de imágenes Landsat?, ¿por qué? ¿Se podría discriminar agua clara de agua con sedimentos mediante imágenes Landsat?, ¿por qué?
- ¿Qué características debería tener un sistema para discriminar, por ejemplo, tipos forestales?
- Si una escena tiene suelo y vegetación, ¿qué características tendría la firma espectral?, ¿se podría discriminar esa firma de otra de vegetación seca?
3.3. Procesamiento digital de imágenes
Durante las últimas décadas se han desarrollado numerosas técnicas de procesamiento y análisis de imágenes para ayudar a su interpretación y para extraer la mayor cantidad de información posible. La elección de técnicas o algoritmos específicos que se utilizarán en el procesamiento y análisis dependerá de los objetivos de cada proyecto individual.
En el procesamiento digital de imágenes el rol humano desempeña un papel crucial en la extracción de información de las imágenes. Aunque las computadoras pueden utilizarse para visualización y digitalización, la interpretación en sí misma es realizada por el operador. En este proceso, el operador humano le indica a la computadora que haga una interpretación de acuerdo con ciertas condiciones. Estas condiciones son definidas a priori por el operador. El procesamiento de imágenes digitales trabaja, principalmente, con cuatro grupos de operaciones básicas: restauración, mejora, clasificación y transformación de imágenes. La restauración de imágenes se ocupa de la corrección y calibración de las imágenes para lograr una representación lo más fiel posible de la superficie de la tierra. La mejora de la imagen trata, de forma general, de modificarla para optimizar su apariencia para la percepción visual. El análisis visual es un elemento clave, incluso en el procesamiento de imágenes digitales. Los efectos de estas técnicas pueden ser decisivos. La clasificación de imagen se refiere a la interpretación de las mismas a través de la definición de una serie de clases o agrupaciones. Este proceso es asistido, actualmente, por computadora (sistemas de información geográfica [SIG])N. Finalmente, la transformación de la imagen se refiere a la derivación de nuevas imágenes como resultado de algún tratamiento matemático de las bandas de imagen en bruto. Para realizar las operaciones aquí enumeradas, es necesario tener acceso a un software de procesamiento de imágenes (Tempfli, Kerle, Huurneman y Jansse, 2009; Chuvieco, 1995).
Estos cuatro grupos de operaciones básicas de imágenes, cuyos principios y características son explicados en esta unidad, serán abordados de forma práctica desde el sistema de información geográfica QGIS en las siguientes unidades.
Aspectos a tener en cuenta cuando trabajamos con imágenes
- Tanto las imágenes analógicas como digitales son una representación bidimensional de objetos en una escena real. Las imágenes de teledetección son representaciones de partes de la superficie terrestre tal como se ven desde el espacio. Las imágenes pueden ser analógicas o digitales. Las fotografías aéreas son ejemplos de imágenes analógicas, mientras que las imágenes satelitales adquiridas con sensores electrónicos son ejemplos de imágenes digitales.
- Una imagen digital está compuesta de una matriz bidimensional de elementos de imagen individuales denominados píxeles que están dispuestos en columnas y filas. Cada píxel representa un área en la superficie de la Tierra. Un píxel tiene un valor de intensidad (cantidad física medida) y una dirección de ubicación en la imagen bidimensional. La intensidad de un píxel se digitaliza y se registra como un número digital (ND). El número de bits determina la resolución radiométrica de la imagen. Por ejemplo, un número digital de 8 bits varía de 0 a 255 mientras que un número digital de 11 bits varía de 0 a 2047. El valor de intensidad detectado debe procesarse para ajustarse a este rango de valor. La dirección de un píxel se denota por sus coordenadas de fila y columna en la imagen bidimensional. Existe una correspondencia de uno a uno entre la dirección de la fila de columnas de un píxel y las coordenadas geográficas (por ejemplo, longitud, latitud) de la ubicación de la imagen.
- Se pueden realizar varios tipos de medición desde el área del suelo cubierta por un solo píxel. Cada tipo de medida forma una imagen que lleva información específica sobre el área. Al "superponer" estas imágenes de la misma área, se forma una imagen multicapa. Cada imagen componente es una capa en la imagen multicapa. Las imágenes multicapa también pueden formarse combinando imágenes obtenidas de diferentes sensores y otros datos secundarios.
- Una imagen multiespectral está compuesta por una serie de capas de imagen, cada capa representa una imagen adquirida en una banda de longitud de onda particular. Por ejemplo, el sensor SPOT HRV que funciona en el modo multiespectral detecta las radiaciones en tres bandas de longitud de onda: las bandas verde (500-590 nm), roja (610-680 nm) e infrarroja cercana (790-890 nm). Una sola escena multiespectral SPOT consta de tres imágenes de intensidad en las tres bandas de longitud de onda. En este caso, cada píxel de la escena tiene tres valores de intensidad correspondientes a las tres bandas.
- Los sensores satelitales más recientes son capaces de adquirir imágenes en muchas más bandas de longitud de onda. Por ejemplo, el sensor MODIS a bordo del satélite TERRA de la NASA consta de 36 bandas espectrales, que cubren las regiones de longitud de onda que van desde el infrarrojo visible, infrarrojo cercano, de onda corta hasta el infrarrojo térmico. Las bandas tienen anchos de banda más estrechos, lo que permite que el sensor capture las características espectrales más finas de los objetivos. Las imágenes que generan estos sensores se denominan imágenes superespectrales.
- Una imagen hiperespectral se compone de unas cien o más bandas espectrales contiguas. La información espectral precisa contenida en una imagen hiperespectral permite una mejor caracterización e identificación de los objetivos. Actualmente, las imágenes hiperespectrales no están disponibles comercialmente desde los satélites.
- La resolución espacial se refiere al grado de detalle con que podemos visualizar dada una imagen determinada. En una imagen digital, la resolución está limitada por el tamaño de píxel, es decir, el objeto observable más pequeño no puede ser más pequeño que el tamaño de píxel. La resolución intrínseca de un sistema de imágenes está determinada principalmente por el campo de visión instantáneo (IFOV) del sensor, que es una medida del área del suelo vista por un solo elemento detector en un instante dado en el tiempo. Sin embargo, esta resolución intrínseca a menudo se degrada por diversos factores. Una imagen de “baja resolución” se refiere a una con un tamaño de resolución pequeño. Los detalles finos se pueden ver en una imagen de alta resolución. Por otro lado, una imagen de “alta resolución” es una con un tamaño de resolución grande, es decir, solo se pueden observar características gruesas en la imagen.
- La resolución radiométrica se refiere al cambio más pequeño en el nivel de intensidad que puede ser detectado por el sistema de teledetección. La resolución radiométrica intrínseca de un sistema de teledetección depende de la relación señal/ruido del detector. En una imagen digital, la resolución radiométrica está limitada por el número de niveles de cuantificación discretos utilizados para digitalizar el valor de intensidad continua (Tempfli, Kerle, Huurneman y Jansse, 2009).
3.3.1. Restauración de imágenes
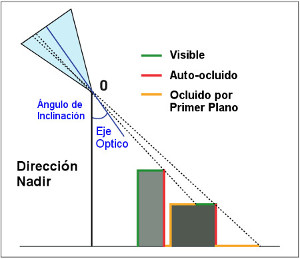
Antes del análisis de los datos, se lleva a cabo, generalmente, un preprocesamiento de las imágenes para corregir cualquier distorsión debida a las características del sistema con el que se han obtenido dichas imágenes. Según los requisitos del usuario, los operadores de las estaciones terrestres pueden llevar a cabo algunos procedimientos de corrección estándar antes de que los datos se entreguen al usuario final. Este procedimiento incluye una corrección radiométrica de los errores producidos por los sensores que generan píxeles incorrectos; una corrección geométrica para arreglar las distorsiones en la imagen global derivada de alteraciones en el movimento del satélite y el mecanismo de captación de los sensores (como la visualización oblicuaN) (imagen 107), y una corrección atmosférica que trata de solucionar la interferencia sistemática de la atmósfera en los valores de los píxeles (Chuvieco, 1995).
Las imágenes oblicuas toman la escena bajo un ángulo de inclinación mucho mayor que las vistas desde el nadir. La inclinación (el ángulo entre el nadir y el eje óptico) mejora la visibilidad de las estructuras verticales (edificios, fachadas, etc.), pero empeora las oclusiones y muestra gradientes de gran escala del primer plano al fondo.
Chuvieco, E. (1995), Fundamentos de Teledetección espacial, segunda edición, Rialp, Madrid, pp. 238-269.
Las imágenes de la superficie terrestre se toman a una gran distancia. Como resultado, la energía electromagnética debe atravesar la atmósfera (y sus condiciones) antes de que llegue al sensor. Dependiendo de las longitudes de onda involucradas y de las condiciones atmosféricas (como materia particulada, contenido de humedad y turbulencia), la energía entrante puede modificarse sustancialmente. El propio sensor puede modificar el carácter de esos datos, ya que puede combinar una variedad de componentes mecánicos, ópticos y eléctricos que sirven para modificar o enmascarar la energía radiante detectada. Asimismo, durante el tiempo de escaneado de la imagen, el satélite está siguiendo una trayectoria sujeta a pequeñas variaciones. La geometría de la imagen está, por lo tanto, en un flujo constante. Finalmente, la señal debe ser enviada de regreso a tierra, recibida y procesada para obtener los datos finales. Durante este proceso, una amplia variedad de perturbaciones sistemáticas aleatorias pueden interactuar para degradar la calidad de la imagen final que se recibe (Chuvieco, 1995).
Corrección radiométrica
La corrección radiométrica es la más sencilla de realizar. Consiste en la eliminación o disminución de distorsiones en el grado de energía electromagnética registrada por cada detector. Una variedad de agentes puede causar distorsión en los valores registrados para los píxeles de la imagen. La corrección radiométrica implica, por un lado, la restauración de líneas o píxeles perdidos y, por otro, la corrección del bandeado de la imagen.
Si se pierde el valor de algún píxel, la solución más rápida es calcularlo como la media de los valores del mismo píxel en las líneas anterior y posterior (no se aconseja utilizar para este cálculo los píxeles contiguos de la misma línea, ya que no son demasiado fiables al haber sido captados por el mismo detector que ha producido el error). De este modo, el cálculo resulta:
NDi,j = round (NDi−1,j + NDi +1,j) /2
donde round indica redondear al número entero más cercano.
Es necesario recordar que las diferentes bandas de una imagen están correlacionadas y que los detectores de dos bandas diferentes no son los mismos. En el caso en el que la imagen alcance un área extensa y cambiante es recomendable calcular los coeficientes de correlación y las desviaciones típicas (sk y sr) alrededor del píxel perdido. Para detectar líneas enteras perdidas se contrasta la media de los ND de una línea con las medias de las líneas anterior y posterior. Para detectar píxeles perdidos se compara el valor de un píxel con los de los 8 píxeles vecinos mediante algún procedimiento digital de filtrado (Alonso, 2006).
El fenómeno del bandeado se produce como consecuencia de una mala calibración entre detectores del sensor, siendo muy visible en las zonas de baja radiancia (zonas marinas, entre otras) y mostrándose como una aparición periódica de una banda más clara u oscura que el resto. Para corregir esto se asume una similitud entre los histogramas recogidos por cada uno de los detectores y una similitud, asimismo, con el histograma global de la imagen de referencia (en caso de que no haya error). Operacionalmente, se calculan, en primer lugar, los coeficientes ak y bk para la corrección lineal de cada uno de los detectores.
bk = s/sk
ak = m − bkmk
m y s son la media y la desviación típica del conjunto de píxeles de la imagen.
mk y sk son la media y la desviación típica de los píxeles obtenidos por el detector k.
Seguidamente, se recalculan los ND de la imagen como:
N D’i,j = ak + bkN D,j, j
asumiendo que la línea i ha sido tomada por el detector k (Alonso, 2006).
Algunas de las distorsiones más comunes que se producen son: valores uniformemente elevados, debido a la bruma atmosférica, que dispersa preferentemente bandas de longitud de onda corta (particularmente, las longitudes de onda azules); rayado (imagen 108), debido a que los detectores salen de calibración; ruido aleatorio, debido al rendimiento impredecible y no sistemático del sensor o la transmisión de los datos; y la caída de la línea de exploración (imagen 109), debido a la pérdida de señal de detectores específicos. También es apropiado incluir aquí los procedimientos que se utilizan para convertir los valores de reflectancia relativa sin unidad, en bruto (conocidos como números o valores digitales) (DN) de las bandas originales en verdaderas medidas de potencia reflectiva (radiancia) (RS).
Afortunadamente, la restauración de la imagenN en los nuevos sensores en general es realizada por los proveedores de datos. Es posible que solo sea necesario aplicar técnicas como la eliminación de errores y la corrección de líneas caídas al trabajar con datos e imágenes antiguas, por ejemplo, los proporcionados desde Landsat MSS. La restauración de la imagen debe aplicarse antes de nuevas correcciones y mejoras (Chuvieco, 1995).
Las imágenes de los escáneres satélitales contienen una variedad de problemas geométricos inherentes, como la desviación (causada por la rotación de la tierra debajo del satélite mientras se escanea una imagen completa) y la distorsión del escáner, derivada del hecho de que el campo instantáneo de la vista (IFOV) cubre más territorio en los extremos de las líneas de exploración, donde el ángulo de visión es muy oblicuo, que en el centro. Con imágenes satelitales comercializadas, como Landsat, IRS y SPOT, la mayoría de los elementos de restauración geométrica sistemática asociada con la captura de imágenes son corregidos por los distribuidores de las imágenes.
Landsat TM. Ejemplo de rayado de líneas (izquierda) e imagen corregida (derecha).

Fuente: <https://equipo-topillos.blogspot.com>
SPOT XS. Ejemplo de caída de línea. En el caso en que el detector falle obteniendo una imagen donde, por ejemplo, cada décima línea es negra, aplicando la corrección de "caída de línea" desde el software se fijarán estéticamente los datos.

Fuente: <https://equipo-topillos.blogspot.com>
Corrección atmosférica
Las interacciones de la radiación solar directa y de la radiación reflejada por la superficie terrestre con los componentes atmosféricos van a interferir con el proceso de transmisión de información en teledetección, originando un “efecto de la atmósfera” que es necesario corregir. La corrección atmosférica intenta evaluar y eliminar las distorsiones que la atmósfera origina en los valores de radiancia que llegan al sensor desde la superficie terrestre. En este sentido, son correcciones que van a basarse en modelos físicos más complejos que los modelos estadísticos utilizados en las correcciones geométricas y radiométricas (Tempfli, Kerle, Huurneman y Jansse, 2009).
Es necesario, en primer lugar, convertir los niveles digitales (ND) almacenados por el sensor en valores de radiancia. Estos ND llegan al sensor a través de una ecuación lineal (de la energía recibida). Para obtener los valores de energía recibida hay que aplicar la inversa de esa ecuación lineal:
\[ L_{sen,k} = a0_k + a1_k ND_k \]
a0k y a1k son los coeficientes de calibración para la banda concreta.
k se refiere a cada una de las bandas del sensor.
Lsen,k es la radiación que recibió el sensor.
Como ejemplo, en la tabla 4 se muestran los valores de estos parámetros para Landsat-5, los valores de irradiancia solar en el techo de la atmósfera (E0k) y de transmitancia (τk) para cada una de las bandas (Alonso, 2006).
Tabla 4. Parámetros para la conversión a reflectividades de las imágenes Landsat
|
Banda |
E0k |
a0k |
a1k |
τk |
TM1 |
1957 |
-1,5 |
0,602 |
0,5 |
TM2 |
1829 |
-2,8 |
1,17 |
0,3 |
TM3 |
1557 |
-1,2 |
0,806 |
0,25 |
TM4 |
1047 |
-1,5 |
0,815 |
0,2 |
TM5 |
219,3 |
-0,37 |
0,108 |
0,125 |
TM7 |
74,52 |
-0,15 |
0,057 |
0,075 |
La radiancia recibida por el sensor no es la radiancia exacta que procede del suelo, ya que esta es reducida por la absorción atmosférica y, a su vez, incrementada por la radiancia que introduce la propia atmósfera (dispersión). Esta relación es expresada a través de la siguiente ecuación:
\[ L_{senk,k} = L_{sue,k} \tau_{k,a} + L_{a,k} \]
La radiación que llega al sensor resulta de multiplicar la radiación procedente del suelo por la transmisividad de la atmósfera ascendente y sumarle la radiancia aportada por la dispersión atmosférica.
Para la estimación de La,k (variable que disminuye al aumentar la longitud de onda) existen dos métodos relativamente sencillos: a) Mínimo del histograma (o sustracción de objetos oscuros). Se trata de localizar en la imagen áreas con reflectancia cercana a cero en el infrarrojo (superficies de agua limpia y profunda, o similares). Estos valores mínimos del histogramaN para las diferentes bandas (k) son una buena aproximación a La, ky por tanto se substraen a los valores originales para conseguir una mejor estimación de Lsue,k (el valor ND mínimo en el histograma de una escena completa se resta de todos los píxeles) (Alonso, 2006). En el caso de Landsat, las bandas 5 y 7 poseen unos valores descartables de La,k y no suelen corregirse. b) Regresión. Se realiza un análisis de regresión de las bandas TM1, TM2 y TM3 respecto a la banda TM4, con la intención de obtener los parámetros de las siguientes ecuaciones:
El histograma es una herramienta fiable y objetiva para evaluar la luminosidad de una imagen. La mayoría de los programas de edición de imágenes ofrecen la opción de mostrar un histograma de la imagen digital. Para profundizar sobre este tema puede consultarse:
TM1 = a1TM4 + b1
TM2 = a2TM4 + b2
TM3 = a3TM4 + b3
Se utiliza bk como estimación de La,k.
Los valores de transmisividad pueden evaluarse a partir de la ecuación
\[ \large \tau_{k,a} = e^{-\tau}_{k^{/cos0_o}} \]
donde θo es el ángulo de observación.
Los valores de irradiancia solar (e) y de transmitancia (τk) para cada banda de Landsat-5 aparecen en la tabla 4 anterior (Alonso, 2006).
Un problema habitual en el sensor es el ruido aleatorio que degrada el contenido de información radiométrica. Por ejemplo, una de las “peculiaridades de la escena” que se registra es cómo se ilumina. Si se considera un área en una latitud apreciable como Argentina, su iluminación será bastante diferente en invierno y en verano (brillo general, sombras, etc.) debido a la diferente elevación del sol (Tempfli, Kerle, Huurneman y Jansse, 2009: 186). La radiación del cielo en el detector produce turbidez en la imagen y reduce el contraste. Para corregir esto se utiliza la corrección de la elevación del Sol (imagen 110). Las diferencias en la iluminación estacional pueden dificultar el análisis de secuencias de imágenes de la misma área, pero tomadas en diferentes momentos o mosaicos de dichas imágenes.
Landsat-7 ETM. Infrarrojo adquirido en diferente ángulo (elevación del sol a 37º parte izquierda de imagen izquierda; elevación solar 42º parte derecha de imagen izquierda). Imagen derecha corregida

Fuente: <https://slideplayer.com/slide/5189523/>
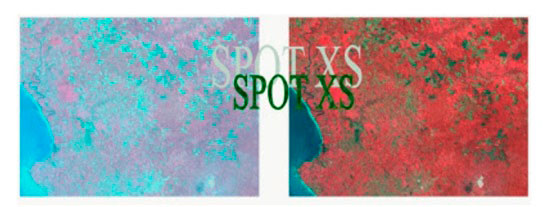
Asimismo, la dispersión atmosférica agrega una “radiación del cielo”. La corrección de la neblina (imagen 111) tiene como objetivo eliminar este efecto de los datos en bruto. La dispersión de Rayleigh difícilmente afectará las grabaciones en la banda espectral roja, mientras que los valores digitales (ND) en la banda azul pueden ser significativamente más elevados. La reducción de la turbidez, por lo tanto, debe realizarse de forma independiente en cada banda de una imagen RS.
SPOT XS. Neblina (izquierda) e imagen corregida (derecha)
Fuente: <https://equipo-topillos.blogspot.com/>
Corrección geométrica
Ni la imagen de satélite ni la fotografías aéreas proporcionan información georreferenciada (información que determina la ubicación de un elemento geográfico concreto). Cada píxel se sitúa en un sistema de coordenadas arbitrario de tipo fila-columna. Es necesario ubicar la imagen en un sistema de coordenadas para poder correlacionarlas con otras capas de información del área y trabajar con ella. De este modo, el proceso de georreferenciación proporcionará a cada píxel una localización en un sistema de coordenadas de referencia (UTM, Lambert, coordenadas geográficas). Tras la georreferenciación se obtiene una nueva capa de información en la que cada columna corresponde con un valor de longitud y cada fila con un valor de latitud (ESRI, 2018).
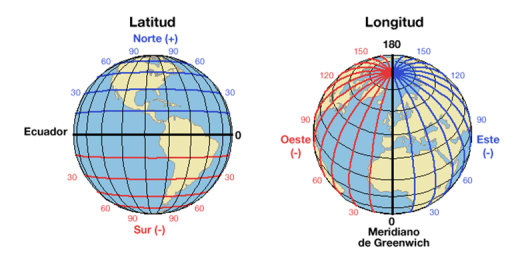
A través de los Sistemas de Referencia de Coordenadas (SRC) cualquier punto de la Tierra puede ser definido por tres números denominados coordenadas. Las proyecciones cartográficas intentan representar la forma de geoide de la superficie de la Tierra, o una parte de ella, en un plano. En general, los SRC se pueden agrupan en: proyectados (también llamados cartesianos o rectangulares), que hacen referencia a cualquier sistema de coordenadas diseñado para una superficie plana como un mapa o una pantalla de computadora –por ejemplo, Transversal de Mercator, Albersequalarea o Robinson–, y geográficos, que utilizan los grados de latitud y longitud y, a veces, un valor de altitud para definir la situación de un punto sobre la superficie terrestre. El sistema de coordenadas geográficas más utilizado es el WGS 84 (imagen 112) (ESRI, 2018).
ESRI (2018), “Georreferenciación y sistemas de coordenadas” [en línea], ArcGISResources, Disponible en <https://resources.arcgis.com/es/help/getting-started/articles/026n0000000s000000.htm>
En el proceso de georreferenciación es necesario corregir las distintas distorsiones sufridas por las imágenes. Las correcciones necesarias para transformar las coordenadas arbitrarias de cada píxel de la imagen (fila-columna) en coordenadas reales (X e Y UTM, por ejemplo) se realizan mediante un par de ecuaciones que hacen corresponder a cada píxel par (f,c) un par (X,Y).
X = f1(f, c)
Y = f2(f, c)
La forma y parámetros de estas funciones van a depender, principalmente, del tipo de enfoque que se escoja para realizar la georreferenciación. Existen dos métodos habituales: la corrección orbital, que modeliza las fuentes de error y su influencia (es necesario conocer con precisión tanto las características de la órbita del satélite como las del sensor); y el enfoque empírico, que modeliza la distribución de errores en la imagen a través de una serie de puntos de control. El primer método resulta automático si se conoce la información necesaria y las ecuaciones de transformación, aunque no es fiable cuando aparecen errores aleatorios (es el que se suministra cuando se pide la imagen ya georreferenciada al proveedor). El segundo método es más sencillo en cuanto a su formulación y corrige mejor los errores aleatorios; sin embargo, resulta mucho más laborioso (Alonso, 2006).
Alonso, F. (2006), “Asignatura de teledetección. Tema 7: Correcciones a las imágenes de satélites”, Universidad de Murcia, pp. 81-86. Disponible en <https://www.um.es/geograf/sigmur/teledet/tema07.pdf>
Es necesario señalar que con las fotografías aéreas el proceso es más complejo. No solo existen distorsiones sistemáticas relacionadas con la inclinación y la altitud, sino que la variación del relieve topográfico lleva a distorsiones muy irregulares (paralaje diferencial) que no es posible eliminar mediante un procedimiento de transformación básico. En estos casos, es necesario usar la rectificación fotogramétrica (imagen 113) para eliminar estas distorsiones y proporcionar medidas precisas (Alonso, 2006).
Proceso de rectificación de una imagen
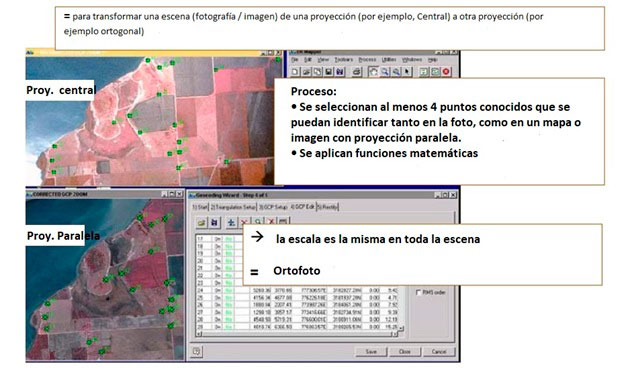
La fotogrametría es “el arte, ciencia y tecnología para la obtención de medidas fiables de objetos físicos y su entorno, a través de grabación, medida e interpretación de imágenes y patrones de energía electromagnética radiante y otros fenómenos” (ASPRS, 2018: 1). Para proporcionar una rectificación completa, es necesario tener imágenes estereoscópicas, es decir, fotografías que se superpongan lo suficiente entre sí (por ejemplo, 60% en la dirección del recorrido y 10% entre líneas de vuelo) para proporcionar dos imágenes independientes de cada parte del área. Usando estos pares de puntos estereoscópicos y puntos de control en el suelo de posición y altura conocidas, es posible recrear de forma integral la geometría de las condiciones de visualización y, de este modo, rectificar las mediciones de dichas imágenes. Las fotografías rectificadas se llaman ortofotos.
El cambio brusco de altitud dentro de una imagen es uno de los principales elementos que producen errores en el proceso de georreferenciación. Si se dispone de un Modelo Digital de Elevaciones (MDE), es decir, una capa rásterN que contiene en cada celdilla su valor de altitud, es posible incorporar este MDE al proceso de georreferenciación (Alonso, 2006).
En los sistemas de información geográfica, los elementos que existen en la naturaleza son representados mediante formas geométricas (puntos, líneas o polígonos, esto es, vectores) o mediante celdillas con información (ráster).
3.3.2. Mejora de la imagen
La mejora de la imagen se refiere a su modificación para hacerla más adecuada a las capacidades de la visión humana o automática y su interpretación. Las mejoras pueden agruparse en dos bloques: procesos de ajuste de contraste, aquellos que tratan de adaptar la resolución radiométrica de la imagen a la capacidad de visualización del monitor, y procesos de filtrado, aquellos que intentan suavizar o reforzar contrastes en la imagen para que los ND de la imagen se asemejen o diferencien más de los correspondientes a los píxeles vecinos.
Chuvieco, E. (1995), Fundamentos de Teledetección espacial, segunda edición, Rialp, Madrid, pp. 270-304.
Ajuste de contraste
Respecto al ajuste de contraste existen dos opciones que derivarán en dos técnicas diferentes de ajuste: el estiramiento de contraste y la compresión de contraste. Al estirar, tratamos de que el rango de ND de la imagen sea menor que el número de visualización (NV) para facilitar la memoria gráfica del ordenador (es la técnica más utilizada). Por otro lado, al comprimir, intentamos que esta capacidad de visualización sea menor que el rango de ND de la imagen (como es habitual utilizar ordenadores con una resolución gráfica en pantalla de 8 bits para cada uno de los colores elementales (rojo, verde y azul), no es necesario utilizar esta técnica).
Existen dos formas de trabajar las mejoras y realces: mediante los operadores puntuales, que son transformaciones que modifican el nivel de gris de cada píxel independientemente de la naturaleza de los píxeles vecinos; y las técnicas de modificación del histograma, que también modifican el nivel de gris de cada píxel, pero, en este caso, con base en el estudio del histograma de la imagen completa.
Normalmente, para realizar una mejora de contraste sobre una imagen suelen tenerse dos intenciones diferentes: la primera es la “mejora temporal”, en la que no queremos cambiar los datos originales, sino que solo queremos obtener una mejor imagen en el monitor para poder realizar una determinada tarea de interpretación o procesamiento. Un ejemplo de esto es la visualización de imágenes para la corrección geométrica. La segunda intención es la de generar nuevos datos, con una mayor calidad visual. Un ejemplo de ello es la producción de ortofotos y el mapeo de imágenes (Chuvieco, 1995).
Dentro de los procesos de estiramiento de contraste, los operadores puntuales maniobran en función de la intensidad de cada píxel de forma independiente y aplican funciones de transformación sobre cada uno de los píxeles a lo largo de una imagen simple (una única banda). Son técnicas sencillas de realce que pueden aplicarse mediante LUT's (Look Up Tables), N (también llamadas CLUT’s (Color Look Up Tables) o tablas indexadas de asignación (imagen 114), en las cuales a cada valor de nivel de gris de entrada se le hace corresponder un valor prefijado de salida. Facilitan la aplicación de transformaciones sin necesidad de calcular el valor de salida de cada píxel. Además de acelerar los cálculos, las LUT's permiten almacenar modificaciones de las imágenes en forma de tablas (solo 256 valores para imágenes cuya resolución radiométrica sea de 8 bits/píxel para cada uno de los colores elementales), sin necesidad de almacenar la imagen completa (Ruiz Fernández, 2018).
En las aplicaciones de análisis de datos, como el procesamiento de imágenes, las tablas de búsqueda (LUT) se utilizan para transformar los datos de entrada en un formato de salida más deseable. Por ejemplo, una imagen en escala de grises del planeta Venus se transformará en una imagen en color para enfatizar las diferencias en su superficie. Estas tablas dan un valor de salida para cada uno los rangos de valores de índice. Una LUT común (mapa de colores o paleta) se utiliza para determinar los colores y los valores de intensidad con los que se mostrará una imagen en particular (Ruiz Fernández, 2018).
Rojo (A), verde (B), azul, (C). Ejemplo de tabla Look-Up para archivo de 16 bits. (No se muestran las líneas 14-65524).
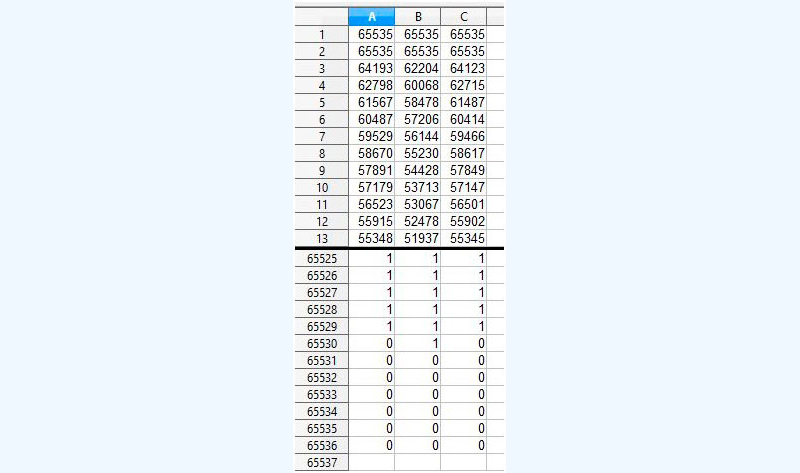
Fuente: By Telecineguy - Open Office, CC BY-SA 4.0 <https://en.wikipedia.org/w/index.php?curid=51589613>
Siguiendo un ejemplo propuesto por el Centre for Remote Imaging, Sensing and Processing (CRISP) de la Universidad de Singapur relacionado con correcciones sobre ajuste de contraste lineal, podemos observar en la imagen siguiente (115) un tinte azulado que le da un aspecto borroso a la visión. Esta apariencia se debe a la dispersión de la luz solar por la atmósfera en el campo de visión del sensor. Este efecto también degrada el contraste entre diferentes landcovers (coberturas terrestres) (CRISP, 2001).

Fuente: CRISP. <https://crisp.nus.edu.sg/~research/tutorial/process.htm>
Para corregir esto (presente en toda la imagen), resulta útil examinar los histogramas de la imagen antes de realizar cualquier mejora de la misma. El eje x del histograma es el rango de los números digitales disponibles, es decir, de 0 a 255. El eje y es el número de píxeles en la imagen que tiene un número digital dado. Los histogramas de las tres bandas de esta imagen (imagen 116) se muestran en las siguientes figuras.
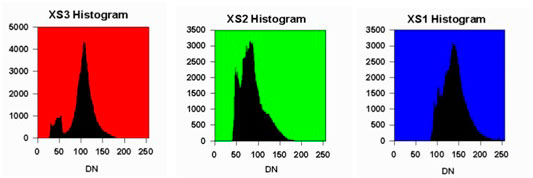
Histograma de la banda XS3 (infrarrojo cercano) (en rojo, izquierda). Histograma de la banda XS2 (roja) (en verde, centro). Histograma de la banda XS1 (verde) (en azul, derecha).
Fuente: CRISP. <https://crisp.nus.edu.sg/~research/tutorial/process.htm>
Es necesario tener en cuenta que el número digital mínimo para cada banda no es cero. Como puede observarse en la imagen anterior (116) cada histograma se desplaza hacia la derecha una cierta cantidad. Este cambio se debe a que el componente de dispersión atmosférica se agrega a la radiación real reflejada desde el suelo. El cambio es particularmente notable para la banda XS1 en comparación con las otras dos bandas debido a la mayor contribución de la dispersión de Rayleigh para la longitud de onda más corta. El número digital máximo de cada banda tampoco es 255. El factor de ganancia del sensor se ha ajustado para anticipar cualquier posibilidad de encontrar un objeto muy brillante. Por lo tanto, la mayoría de los píxeles de la imagen tienen números digitales muy por debajo del valor máximo de 255 (CRISP, 2001).
Teniendo esto en cuenta, la imagen se puede mejorar mediante un simple estiramiento del contraste lineal (una de las técnicas más habituales). En este método, se elige un valor de umbral de nivel para que todos los valores de píxeles por debajo de este umbral se asignen a cero. También se elige un valor de umbral superior para que todos los valores de píxeles por encima de este umbral se asignen a 255. Todos los demás valores de píxeles se interpolan linealmente entre 0 y 255. Los umbrales superior e inferior generalmente se eligen para que sean valores cercanos al mínimo y valores máximos de píxel de la imagen. La tabla de transformación de nivel de gris (imagen 117) se muestra en el siguiente gráfico (Tempfli, Kerle, Huurneman y Jansse, 2009).
Tabla de transformación de nivel de gris para realizar el estiramiento de contraste lineal de gris de las tres bandas de la imagen. Línea roja: banda XS3; línea verde: banda XS2; línea azul: banda XS1.
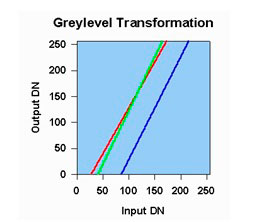
Fuente: CRISP. <https://crisp.nus.edu.sg/~research/tutorial/process.htm>
El resultado de aplicar el estiramiento lineal se muestra en la siguiente imagen (118). Se debe tener en cuenta que el aspecto nebuloso general se ha eliminado, excepto en algunos sectores cercanos a la parte superior de la imagen. El contraste entre diferentes características ha sido notablemente mejorado.
Imagen SPOT multiespectral después de la mejora mediante un simple estiramiento de contraste lineal.

Fuente: CRISP. <https://crisp.nus.edu.sg/~research/tutorial/process.htm>
Como se señalaba anteriormente, el estiramiento de contraste lineal es una transformación de escala de grises simple donde el ND de entrada más bajo de interés se convierte en 0 y el ND de interés más alto se convierte en 255 (imagen 120). El monitor mostrará 0 como negro y 255 como blanco. Como ND de entrada más bajo y más alto, a menudo tomamos los valores de 1% y 99%.
La relación funcional entre los ND de entrada y los valores de píxeles de salida es lineal, como se muestra en la imagen 120(a). La función que aparece en la primera fila de la imagen 120 (en el contexto del histograma de la imagen de entrada) se denomina función de transferencia. Muchos paquetes de software de procesamiento de imágenes permiten manipular gráficamente la función de transferencia para que pueda obtenerse una apariencia de imagen a gusto del usuario. La implementación de la transformación se puede hacer en una tabla de consulta tal como puede observarse en la imagen 119 (Tempfli, Kerle, Huurneman y Jansse, 2009).
Ejemplos del método de estiramiento de contraste para redimensión de la imagen en distintas intensidades entre los percentiles 2 y 98
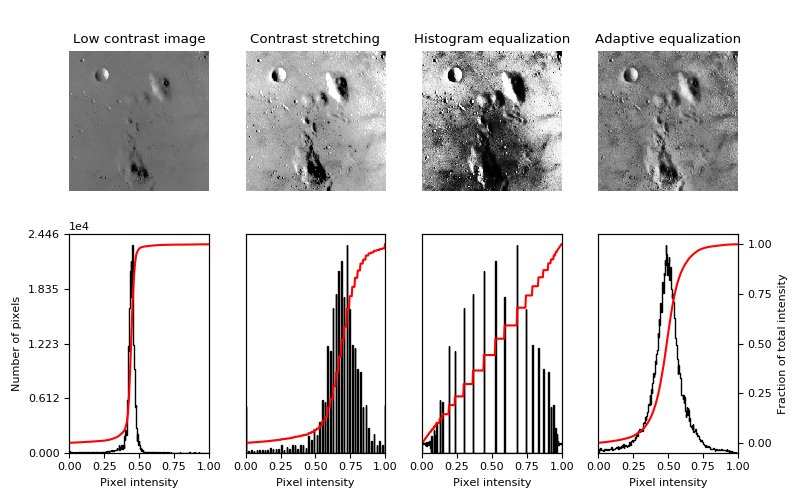
La ecualización del histograma (imagen 120 [b]) es otra técnica de estiramiento o expansión de contraste, no lineal. Varios paquetes de procesamiento de imágenes lo ofrecen como una función predeterminada. En esta expansión del contraste, la asignación del color no se realiza en relación con el valor digital del píxel, sino mediante el orden que ocupa en la distribución de valores. Es decir, se considera la distribución de frecuencias en los ND originales. El objetivo es generar una LUT en la cual cada NV posea, de forma aproximada, el mismo número de ND de la imagen. Con base en este criterio, el NV asignado a cada ND está en proporción no solo a este valor, sino también a su frecuencia. Si la imagen original presenta una distribución gaussiana (distribución normal), es posible obtener mejores resultados (Tempfli, Kerle, Huurneman y Jansse, 2009: 195-197).
a) Imagen e histograma acumulado originales (a). Imagen e histograma acumulado tras un proceso de ecualización (b).
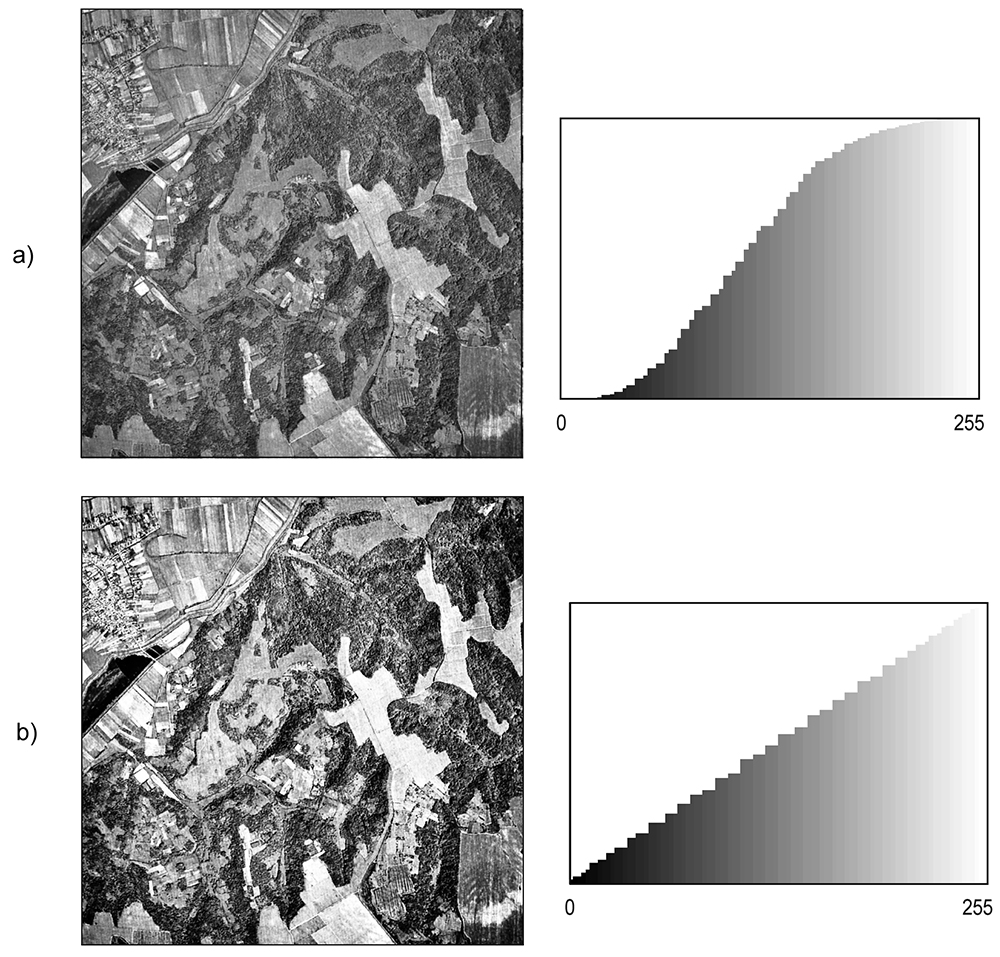
Es importante tener en cuenta que la mejora del contraste (por estiramiento lineal o ecualización de histograma) tan solo amplifica las pequeñas diferencias en los datos para que podamos diferenciar visualmente las características, pero no aumenta el contenido de información de los datos (Tempfli, Kerle, Huurneman y Jansse, 2009: 197).
Filtrado
Los filtros son utilizados, al igual que las técnicas anteriormente señaladas, para obtener una mejora visual de las imágenes. Podemos agrupar los filtros en dos tipos según la modificación que realizan: a) los filtros de suavizado, que producen un efecto de desenfoque, restando definición a la imagen y atenuando las diferencias entre píxeles vecinos; y, en contraste, b) los filtros de realce, que producen un efecto de enfoque, aumentando la definición de la imagen. Acentúan las diferencias de intensidad entre píxeles vecinos (Olaya, 2014: 433).
Filtros de suavizado
Los filtros de suavizado (también llamados filtros de paso bajo) producen una pérdida de foco en la imagen. Esto se logramediante la reducción de las diferencias entre píxeles contiguos (por ejemplo, utilizando un filtro de media (imagen 121). El núcleo de este filtro puede expresarse de la siguiente forma:
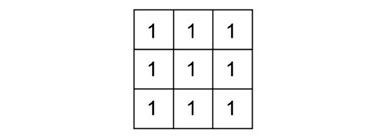
El efecto del filtro de mediaN aplicado sobre una capa de elevación, “redondeaba” el relieve (Olaya, 2014: 434). Al ser aplicado sobre una imagen le infiere un aspecto borroso. La cantidad de suavizado puede ser controlada mediante el tamaño de la ventana. Otra forma de modificar el efecto del suavizado, limitándolo, es otorgando más peso al píxel central (imagen 123). Para ello, es posible utilizar un núcleo como el que se muestra a continuación (122):
Como el filtro de media es sensible a los valores extremos de la ventana, suele ser sustituido por un filtro de mediana, ya que este no resulta sensible a los valores extremos muy alejados de la media (outliers). Asimismo, garantiza que el valor resultante sea un valor que existe como tal en la ventana de píxeles circundantes. El filtro de mediana no puede expresarse mediante un núcleo (Olaya, 2014: 434).
Núcleo de filtro de media con peso en píxel central
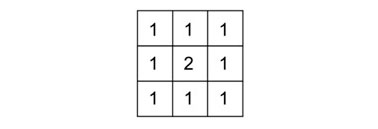
Núcleo de filtro de media con peso en píxel central

La aplicación de un filtro puede, también, eliminar el ruido de una imagen. Un tipo de ruido habitual es el conocido como sal y pimienta, que resulta, con frecuencia, al segmentar imágenes. La imagen de salida contiene únicamente valores 1 (representados en blanco) y 0 (representados en negro).“Es normal que en la segmentación aparezcan píxeles con uno de dichos valores, rodeados por píxeles del otro, es decir píxeles completamente aislados. Esto da la sensación de una imagen sobre la que se han 'esparcido' píxeles blancos (sal) sobre la parte negra, o negros (pimienta) sobre la parte blanca” (imagen 124) (Olaya, 2014: 435).
Ruido “sal y pimienta” (izquierda). Eliminación del ruido mediante filtro de mediana (derecha).

Filtros de realce
Los filtros de realce, al contrario de los anteriores, tienen la característica de acentuar las diferencias entre píxeles adyacentes, logrando un efecto de enfoque. Por tanto, la definición aumenta (imagen 125).
Imagen tras la aplicación de un filtro de realce
Filtros de detección de bordes
Los filtros de detección de bordes posibilitan la localización de las zonas donde se producen transiciones bruscas de intensidad.
Aplicación de un filtro de detección de bordes (laplaciano) sobre la imagen original (izquierda) y la imagen ecualizada (derecha)

Existen filtros de detección de bordes que tienen su base en “el análisis de las segundas derivadas de la función que los niveles digitales definen y la detección de puntos donde esta se anula” (filtro laplaciano) (imagen 126). Otros filtros se basan en “el estudio del gradiente (la primera derivada) de forma que se realcen las zonas en las que existan variaciones notables entre las intensidades de píxeles contiguos” (filtros de Sobel) (imagen 127) (Olaya, 2014: 438).
Aplicación de un filtro de Sobel vertical (izquierda) y horizontal (derecha)

Fusión de imágenes
La fusión de imágenes se refiere a los distintos procesos que permiten integrar información procedente de distintas fuentes de datos en una sola imagen. Esta imagen final facilita la interpretación y análisis de la información de base al contener las características más destacables de todas las imágenes originales. Por ejemplo, a través de la fusión pueden generarse imágenes sintéticas que sean capaces de combinar imágenes de alta resolución espacial con otras de alta resolución espectral, con la intención de que presenten alta resolución en ambos componentes. Unir estas mediante un proceso de fusión es una forma de obtener imágenes de mejor calidad. “El uso combinado de imágenes pancromáticas e imágenes multiespectrales como las del satélite Landsat es una práctica habitual a la hora de aplicar este método de fusión” (Olaya, 2014: 440).
Se utilizan, principalmente, tres métodos: a) transformación IHS; b) por componentes principales; y c) Brovey.
Transformación IHS
El formato IHSN (imagen 128) es el que más se asemeja a cómo percibimos los distintos colores, y se basa en los siguientes componentes: a) intensidad (I), expresa el brillo del color; b) tono (H), indica la longitud de onda predominante de dicho color; c) saturación (S), muestra la “pureza” del color. Valores altos indican una alta presencia de blanco (Mather y Koch, 1999).
Intensity, Hue, Saturation (Intensidad, Tono, Saturación).
Dadas dos imágenes RGB, una de ellas con mayor información espacial y otra con mayor información espectral, puede realizarse una fusión empleando una transformación IHS siguiendo los pasos descritos a continuación […]: se remuestrea la imagen de menor resolución espacial a las dimensiones de la de mayor resolución, o bien ambas a un tamaño de píxel intermedio entre los de ambas imágenes. Ese será el tamaño de píxel de la imagen resultante, mejorando así el de la imagen que aporta la información espectral. Se convierten las imágenes al formato IHS. Lo habitual es que la imagen con mayor resolución espacial sea de una única banda, con lo que no es necesaria conversión alguna. Se sustituye en la imagen con la información espectral la banda de intensidad I por la banda de intensidad de la otra imagen. Se aplica una transformación inversa para pasar de nuevo al formato RGB (Olaya, 2014: 441).
Fusión de imágenes mediante transformación IHS
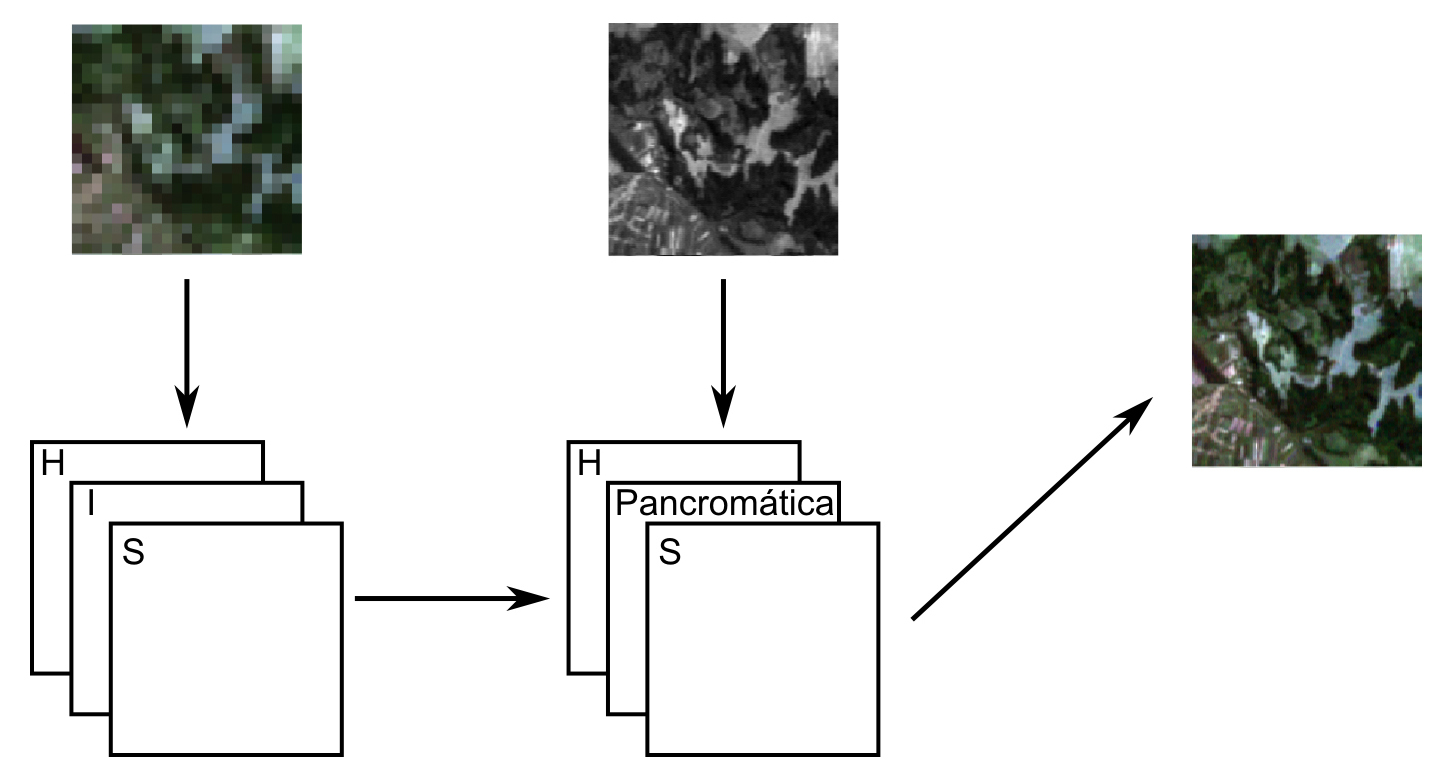
Carper, W. J., Lillesand, T. M. y Kieffer, R. (1990), “The Use of Intensity-Hue-Saturation Transformations for Merging SPOT Panchromatic and Multispectral Image Data”, Photogrammetric Engineering and Remote Sensing, 56: 459-467.
Transformación por componentes principales
El método de análisis de componentes principales convierte un conjunto de capas (o bandas) intercorrelacionadas en un nuevo conjunto con un menor número de capas y menos correlacionadas. Es decir, “sustituye las variables originales por otras entre las que no existe correlación, cada una de las cuales explica un porcentaje concreto de la varianza global” (Olaya, 2014: 442). Uno de los procesos más habituales es la transformación de Brovey, aunque su procedimiento es distinto a los anteriores: opera banda a banda, aumentando la resolución de estas de forma individual, de modo que combinando las bandas resultantes se obtiene la imagen sintética buscada (Olaya, 2014: 442).
Roller, N. y Cox, S. (1980), “Comparison of Landsat MSS and merged MSS/RBV data for analysis of natural vegetation”, Proc. of the 14th International Symposium on Remote Sensing of Environment, San José, Costa Rica, 23-30, April, pp. 1001-1007.
3.3.3. Clasificación digital
La elaboración de una serie de clases relativas a litología, tipos de vegetación, usos del suelo, etc., sobre el área de estudio es uno de los objetivos fundamentales en teledetección. La clasificación de imágenes necesitará de la interpretación asistida por computadora de las imágenes obtenidas a través de sensores remotos. Aunque algunos procedimientos pueden incorporar información sobre características de imagen –tales como textura y contexto–, en la mayoría de los casos la clasificación de imágenes se basa únicamente en la detección de firmas espectralesN (es decir, patrones de respuesta espectral) de las clases de la cobertura terrestre. El resultado de esto va a depender de dos cosas: a) la presencia de firmas distintivas para las clases de cobertura de la tierra en el conjunto de bandas que se está utilizando; y b) la capacidad de distinguir de forma confiable estas firmas de otros patrones de respuesta espectral que puedan estar presentes (Alonso, 2006; Chuvieco, 1995).
Llamamos firma espectral al patrón espectral que origina la forma en la que un objeto refleja, emite o absorbe la energía em (espectro electromagnético). Esta firma permite identificar y excluir diferentes objetos de la superficie terrestre.
Una vez que se han aplicado todo tipo de correcciones (radiométricas y geométricas) sobre los datos, pueden utilizarse dos métodos diferentes (aunque complementarios) para elaborar una clasificación (generación de clases): la clasificación supervisada y la clasificación no supervisada. En el caso de la supervisada, se parte de una serie de clases previamente definidas y se obtienen sus signaturas espectrales. Generalmente, el sistema de software delimita los tipos específicos de cobertura terrestre basados en datos de caracterización estadística extraídos de ejemplos conocidos en la imagen. En la clasificación no supervisada, no se establece ninguna clase a priori, aunque es necesario determinar el número de clases que se quiere generar, y permitir que las defina un procedimiento automático. El software utilizará un agrupación en clústeres (un algoritmo de clasificación automática multivariante) para identificar los tipos de cubiertas terrestres más comunes, y el analista se encargará de proporcionar interpretaciones de esos tipos de coberturas en una etapa posterior (Alonso, 2006; Chuvieco, 1995).
Chuvieco, E. (1995), Fundamentos de Teledetección espacial, segunda edición, Rialp, Madrid, pp. 325-340.
Clasificación supervisada
El proceso de clasificación supervisada conlleva las siguientes etapas: a) un análisis de componentes principales para sintetizar la información contenida en las bandas e incluso eliminar alguna del análisis. b) La generación de clases y signaturas espectrales características donde se realiza una clasificación no supervisada en la que se utilizan algoritmos matemáticos de clasificacón automática (algoritmos de clustering, principalmente, que fracciona el espacio de las variables en una serie de regiones minimizando la varianza interna de los píxeles de cada región; de esta forma, cada región va a definir una clase espectral). Asimismo, se seleccionan áreas de entrenamiento para clasificación supervisada, áreas de las que se conoce a priori la clase a la que pertenecen y que se utilizarán para crear una signatura espectral propia de cada una de ellas (clases informacionales). Seguidamente, se comparan las signaturas espectrales características de las clases informacionales con las clases espectrales. Aquí se determinarán las clases con las que se trabajará (es preferible trabajar con clases espectrales que con clases informacionales). c) La clasificación en sí misma a través de diferentes métodos: no estadísticos (mínima distancia), estadísticos clásicos (máxima probabilidad), algoritmos basados en inteligencia artificial (lógica borrosa). d) Finalmente, se lleva a cabo una evaluación de la precisión de la clasificación realizada (imagen 129) (Alonso, 2006).
Imagen MSS y definición supervisada de clases
Clasificación no supervisada
En contraste con la clasificación supervisada, donde informamos al sistema sobre el carácter (la firma) de las clases de información que estamos buscando, la clasificación no supervisada no requiere información anticipada sobre las clases de interés, sino que examina los datos y los divide en los grupos espectrales o en las agrupaciones más presentes en los datos. Es necesario, posteriormente, identificar estos grupos como clases de cobertura terrestre a través de una combinación de familiaridad con la región y visitas a campo.
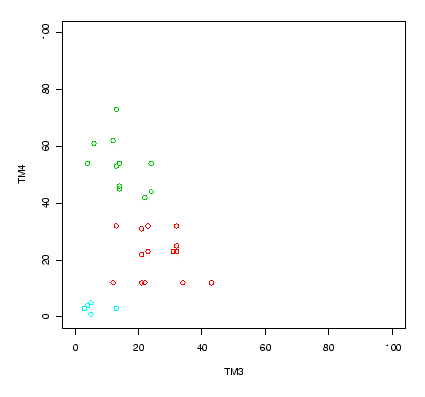
Operativamente, se utilizan algoritmos de clasificación automática multivariante como el clustering. Este consta de N pasos, siendo N el número total de individuos a clasificar. En cada uno de los pasos se van a identificar los dos individuos más próximos, se crea una clase con ellos y se sustituyen por el centroide de la clase resultante. Así, cada paso analiza un individuo menos que el anterior, ya que los individuos son sustituidos por clases. El proceso finaliza cuando se ha alcanzado un número de clases igual al número de clases que se estableció a priori (imagen 130) (Alonso, 2006).
Distribución de los píxeles de las diferentes áreas de entrenamiento
Dendrograma a partir de los píxeles de las áreas de entrenamiento
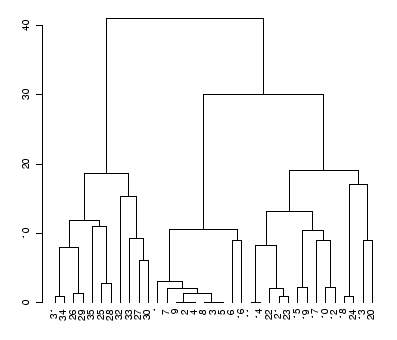
El resultado final de un proceso de clustering suele ser un dendrograma (imagen 131) que muestra cómo los diversos individuos se agrupan en clases (en primer lugar, los que están a una menor distancia, los más parecidos) y cómo, después, las clases se unen entre sí. A partir de un dendrograma es posible escoger el número de clases que se van a mantener. Por ejemplo, en la imagen se observan claramente tres grupos identificados. Cuando este proceso se utiliza en teledetección se clasifican todos los píxeles; no es muy práctica la salida de la información a través de un dendrograma, en su caso, la información sale mediante un mapa en el que los píxeles surgen adjudicados a las diferentes clases (por ello es imprescindible elegir a priori el número de clases) (Alonso, 2006).
Hay que tener en cuenta que un análisis de clúster realiza la clasificación de imágenes compuestas que combinan las bandas de información más útiles, pero estos clústeres producidos por la clasificación no supervisada no son clases de información, sino clases espectrales (es decir, agrupan características [píxeles] con patrones de reflectancia similares). Por lo tanto, es necesario reclasificar las clases espectrales en clases de información. Por ejemplo, el sistema podría identificar las clases de asfalto y cemento que el analista agruparía, más adelante, creando una clase de información llamada pavimento (Alonso, 2006).
Una etapa fundamental en el proceso de clasificación no supervisada, al igual que en la supervisada, es la evaluación de la precisión de las imágenes finales producidas.
Siguiendo con las imágenes de ejemplo propuestas por el Centre for Remote Imaging, Sensing and Processing (CRISP) de la Universidad de Singapur, que se utilizaron en el apartado anterior sobre estiramiento del contraste lineal, la siguiente imagen muestra un ejemplo de un mapa temático (imagen 133). Este mapa se derivó de la misma imagen SPOT multiespectral del área de prueba (imagen 132) utilizando un algoritmo de clasificación no supervisado (CRISP, 2001).

Imagen multiespectral SPOT del área de prueba
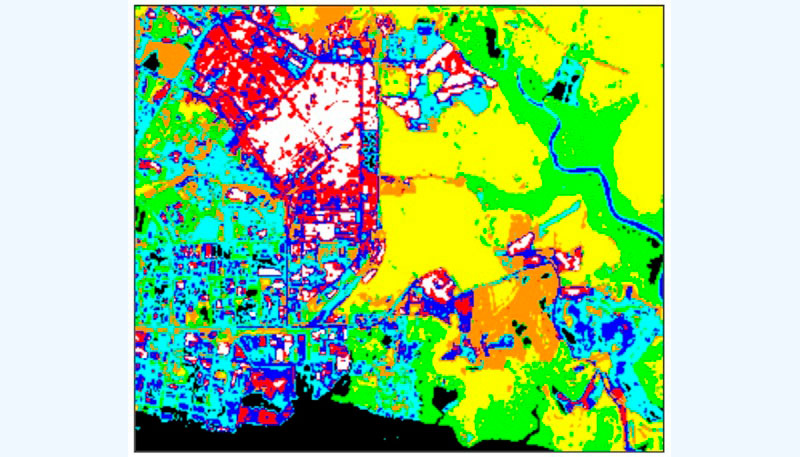
Mapa temático derivado de la imagen SPOT utilizando un algoritmo no supervisado de clasificación.
Una asignación posible de tipos de cobertura terrestre a las clases temáticas se muestra en la siguiente tabla 5. La precisión del mapa temático derivado de las imágenes de sensores remotos debe verificarse mediante observación de campo.
Tabla 5. Asignación de clase (color) por cobertura terrestre
|
Clase Nº (color en el mapa) |
Tipo de cubierta terrestre |
|
1 (negro) |
Agua clara |
|
2 (verde) |
Bosque denso con dosel cerrado |
|
3 (amarillo) |
Bosque poco denso |
|
4 (naranja) |
Hierba |
|
5 (cian) |
Suelo desnudo |
|
6 (azul) |
Agua turbia, suelo desnudo, áreas edificadas |
|
7 (rojo) |
Suelo desnudo, áreas edificadas |
|
8 (blanco) |
Suelo desnudo, áreas edificadas |
Las características espectrales de estas clases de coberturas terrestres pueden observarse en los gráficos siguientes (imagen 134). El primer gráfico muestra los valores de píxeles medios de la banda XS3 (infrarrojo cercano) frente a la banda XS2 (roja) para cada clase. El segundo gráfico contiene los valores de píxeles medios de las bandas XS2 (rojo) frente a XS1. También se muestran las desviaciones estándar de los valores de píxeles para cada clase.
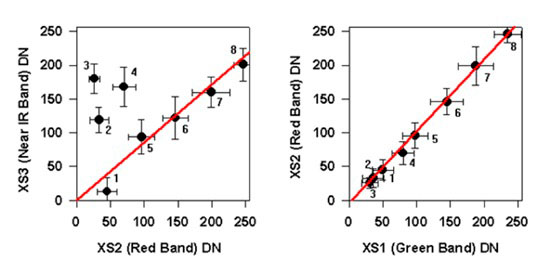
Diagrama de dispersión de los valores medios de píxeles para cada clase de cobertura terrestre.
En el diagrama de dispersión de las medias de clase en las bandas XS3 y XS2, los puntos de datos para las clases de cobertura terrestre sin vegetación generalmente se encuentran en una línea recta que pasa por el origen (imagen 134). Esta línea se llama la “línea del suelo”. Las clases de cobertura del suelo con vegetación se encuentran por encima de la línea del suelo debido a la mayor reflectancia en la región del infrarrojo cercano (banda XS3) en relación con la región visible. En el diagrama de dispersión XS2 (rojo visible) frente a XS1 (verde visible), todos los puntos de datos se encuentran, mayoritariamente, en una línea recta. Esta gráfica muestra que las dos bandas visibles están altamente correlacionadas. Las áreas con vegetación y el agua clara son generalmente oscuras, mientras que las otras clases de cobertura terrestre no planeadas tienen un brillo variable en las bandas visibles (CRISP, 2001; Chuvieco, 1995).
3.3.4. Transformación de la imagen
El procesamiento digital de imágenes ofrece una gama ilimitada de posibles transformaciones sobre los datos obtenidos de forma remota. En este apartado nos centraremos en dos procesos: los índices de vegetación y el análisis de componentes principales, debido a su importancia y su aplicación habitual en múltiples campos (medioambiente, usos del suelo, etc.).
Chuvieco, E. (1995), Fundamentos de Teledetección espacial, segunda edición, Rialp, Madrid, pp. 304-324.
Índices de vegetación
La vegetación es uno de los elementos de la superficie terrestre del que más se ha ocupado el análisis de imágenes. Uno de los principales parámetros utilizados para recoger información sobre esta cobertura son los denominados índices de vegetación. Estos índices permiten identificar la vegetación (y su actividad) en una zona concreta a través de sus valores (que están en relación con dicha actividad). Son usados para acentuar en la imagen las áreas con vegetación a través de la combinación de diferentes bandas de una imagen multiespectral. Una de estas combinaciones se corresponde con la relación de la banda del infrarrojo cercano y la banda roja. A esta relación se la conoce como Índice de Vegetación Proporcional (RVI) (Chuvieco, 1995). Se calcula mediante:
RVI = NIR / Rojo
[…] Para ello, utilizan los valores de reflectancia correspondientes a las distintas longitudes de onda, interpretando estas en relación con la actividad fotosintética. En términos generales, un índice de vegetación puede definirse como un parámetro calculado a partir de los valores de la reflectividad a distintas longitudes de onda y que pretenden extraer de los mismos la información relativa a la vegetación, minimizando las perturbaciones debidas a factores tales como el suelo o la atmósfera. (Olaya, 2014: 453)
Las plantas absorben radiación en las regiones visibles del espectro –en concreto en la región del rojo– para obtener energía y realizar la fotosíntesis mientras reflejan radiaciones de menor frecuencia como las del infrarrojo, por no resultar útiles para la actividad fotosintética. En teledetección, esto se traduce como altos valores de reflectancia en las bandas de imágenes de satélite correspondientes a la zona del infrarrojo y, por el contrario, valores muy bajos en la banda del rojo en caso de que exista vegetación. Este es el fundamento de los índices de vegetación para localizarla sobre la superficie terrestre.
En la imagen 135 puede observarse el uso del falso color, utilizando el color rojo para las bandas del infrarrojo cercano, y el color verde para los canales del rojo, verde y azul respectivamente (modelo RGB). Como resultado, las zonas con cultivos de alto vigor vegetativo aparecen con un tono rojo intenso que permite su rápida identificación (Olaya, 2014).
Imagen falso color con esquema RGB=NRG

Gilabert, M., González-Piqueras, J. y García-Haro, J. (1997), “Acerca de los índices de vegetación”, Revista de Teledetección, 8: 35-45.
Hay que tener en cuenta que, según el tipo de sensor, las bandas del rojo y del infrarrojo cercano variarán (por ejemplo, en el sensor Landsat, la banda del rojo es la 3 y la del infrarrojo cercano es la 4). Con base en los valores de las bandas (rojo e infrarrojo cercano) se pueden distinguir dos grupos de índices: a) formulaciones que emplean únicamente las bandas del rojo y el infrarrojo cercano (índices basados en distancia, o intrínsecos); y b) formulaciones que también utilizan los parámetros de la denominada línea del sueloN (índices basados en pendiente) (Gilabert, González-Piqueras y García-Haro, 1997).
Una línea de suelo (línea de referencia) se define por la amplia gama de suelos que tienen reflectividades bidireccionales linealmente relacionadas. Por ejemplo, en un espacio bidimensional de reflectividades espectrales infrarrojo próximo (IRP) - rojo (R), la línea de suelo, se define con dos puntos, A y B, donde A corresponde a zonas secas y B a húmedas. En dicho espacio bidimensional, se sitúan los puntos C, D y E que representan zonas con vegetación. Las distancias C - D - E con sus respectivos C0 - D0 - E0 (situados sobre la línea de suelo), están directamente relacionadas con la densidad del cultivo en C, D y E, respectivamente) (Chuvieco, 1995).
El índice de vegetación más utilizado es el NDVI (diferencia normalizada entre la reflectividad de la banda infrarroja y la roja) (imagen 136). Es un índice de cálculo sencillo (basado en la distancia), que dispone de un rango de variación fijo (entre –1 y +1), posibilitando establecer umbrales y comparar imágenes, entre otros. Se expresa de la siguiente forma:
\[ NDVI = \frac{IR \ – R}{IR + R} \]
R e IR son las reflectancias correspondientes al rojo e infrarrojo, respectivamente.
Asimismo, el NDVI puede emplearse para conocer otros parámetros relativos a la vegetación.
Factores tales como el vigor vegetativo, el estado fitosanitario o el contenido en agua de las hojas influyen en la forma en cómo los procesos fotosintéticos se producen. Esto tiene un efecto directo sobre las radiaciones emitidas en las distintas longitudes de onda, y muy particularmente en las empleadas para la definición de los índices de vegetación. Por ello, son una valiosa fuente de información acerca de las variables propias de la vegetación (Olaya, 2014: 477).
Índice de vegetación de diferencia normalizada (NDVI)

Rouse, J., Haas, R., Schell, J. y Deering, D. (1973), “Monitoring vegetation systems in the Great Plains with ERTS”, Procceding of the Third ERTS Symposium, NASA SP-351 I, pp. 309-317.
A pesar de su sencillez, el NDVI es sensible a la reflectividad del suelo sobre el que se sitúa la vegetación. Por ejemplo, en una zona con baja densidad de vegetación, la reflectividad que le correspondería a un píxel en la banda infrarroja (IRC) y en la banda roja (R) vendrían determinados, en su mayor parte, por el suelo, con una leve variación debida por la vegetación. Como consecuencia, un índice de vegetación (IV) de esa zona mostraría resultados muy parecidos a los del suelo desnudo imposibilitando la detección de vegetación (es un problema grave cuando la cubierta vegetal es menor del 50%). Para resolverlo se han desarrollado una serie de índices de vegetación que consideran la reflectividad del suelo a través de la separación de la información, por un lado, de la vegetación y, por otro, del suelo que está bajo ella. Uno de los IV más utilizado que tiene en cuenta el substrato es el Índice de Vegetación Perpendicular (PVI) (índice basado en pendiente) de Richardson y Wiegand (1977) (Sánchez Rodríguez et al., 2000: 166-167).
El cálculo del PVI no presenta demasiada dificultad tras conocer la ecuación correspondiente a la línea del suelo, de la forma IRCsuelo = a Rsuelo + b, ya que basta con aplicar la fórmula:
PVI = a IRC – R + b / (a2 + 1) ½
La línea del suelo se calcula a partir de la reflectividad en el rojo y el infrarrojo cercano de una serie de píxeles de suelo desnudo localizados en la imagen, por análisis de regresión en el que la banda roja se toma como variable independiente y la banda infrarroja como variable dependiente. El fundamento en el que reside el uso de la línea de suelo y su incorporación a los índices de vegetación puede comprenderse analizando la imagen 137. Los puntos de la gráfica (imagen 137) corresponden a los valores en las bandas del rojo y el infrarrojo cercano para los píxeles sobre zonas de suelo desnudo. A estos se ajusta la recta r mostrada. Los puntos que se sitúan sobre la recta (punto X) se asocian al suelo desnudo; por el contrario, los que se sitúan lejos de ella indican mayor vegetación, cuanto mayor sea la distancia de alejamiento (punto X’) (Olaya, 2014; Sánchez Rodríguez et al., 2000).
Si en un punto concreto no hay vegetación, ese punto se representará sobre la línea del suelo. Pero si hay una cierta cantidad de vegetación, la reflectividad de esa zona en el rojo será más baja que la del suelo desnudo, y en el infrarrojo será más alta, por lo que el punto quedará representado alejado de la línea del suelo. Cuanto más lejos esté de la línea del suelo, más vegetación habrá en el píxel; por eso, se toma como una medida de la cantidad de vegetación la distancia perpendicular desde cualquier punto a la línea del suelo (Sánchez Rodríguez et al., 2000: 167).
Representación gráfica de la línea de suelo, un punto correspondiente a suelo desnudo (X) y un punto correspondiente a la presencia de cierta vegetación (X′).
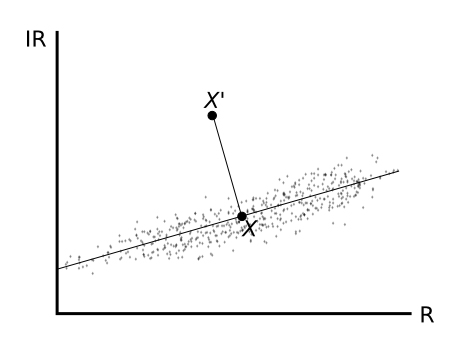
Análisis de componentes principales
El análisis de componentes principales (ACPN) es otra técnica estadística de gran interés en la transformación de las imágenes.
EL ACP también es conocido como transformación de Karhunen-Loeve o de Hotelling.
Mediante el ACP se trata de disminuir la dimensionalidad de un conjunto de variables reduciéndolo a uno más pequeño para evitar la pérdida de información. Su objetivo es el de «resumir» la información que contienen las variables eliminando partes redundantes o superfluas, pero sin eliminar información relevante. Esta trasformación es útil para reducir el volumen de datos y facilitar las operaciones de análisis, interpretación y manejo de las variables (Olaya, 2014).
En el caso de imágenes con elevado número de bandas (multiespectrales e hiperespectrales), la representación de estas no puede hacerse empleando todas las bandas, sino que deben prepararse composiciones, como máximo, de tres bandas. Utilizar un ACP va a permitir reducir las bandas a un conjunto de tres con la máxima información posible, método mucho más adecuado que escoger tres de forma aleatoria (con la pérdida de información que esto conlleva).
De este modo, para el usuario final de productos de teledetección, el objetivo del ACP es generar una o varias imágenes que aumenten la posibilidad de diferenciar distintas coberturas en la superficie terrestre. Por ello, es preferible usar, en lugar de algunas bandas de la imagen aleatoria, los componentes principales 1, 2 y 3 en la secuencia RGB respectivamente. Por otro lado, esta técnica incrementa la eficiencia en las operaciones de las clasificaciones previas porque reduce la dimensionalidad de los datos. Complementariamente, desde el punto de vista estadístico, el ACP facilita una primera interpretación sobre los ejes de variabilidad de la imagen que permitirá identificar tanto los rasgos comunes en las bandas como los que son específicos de algún grupo de ellas (Olaya, 2014).
Proceso orientado a la obtención de componentes principales
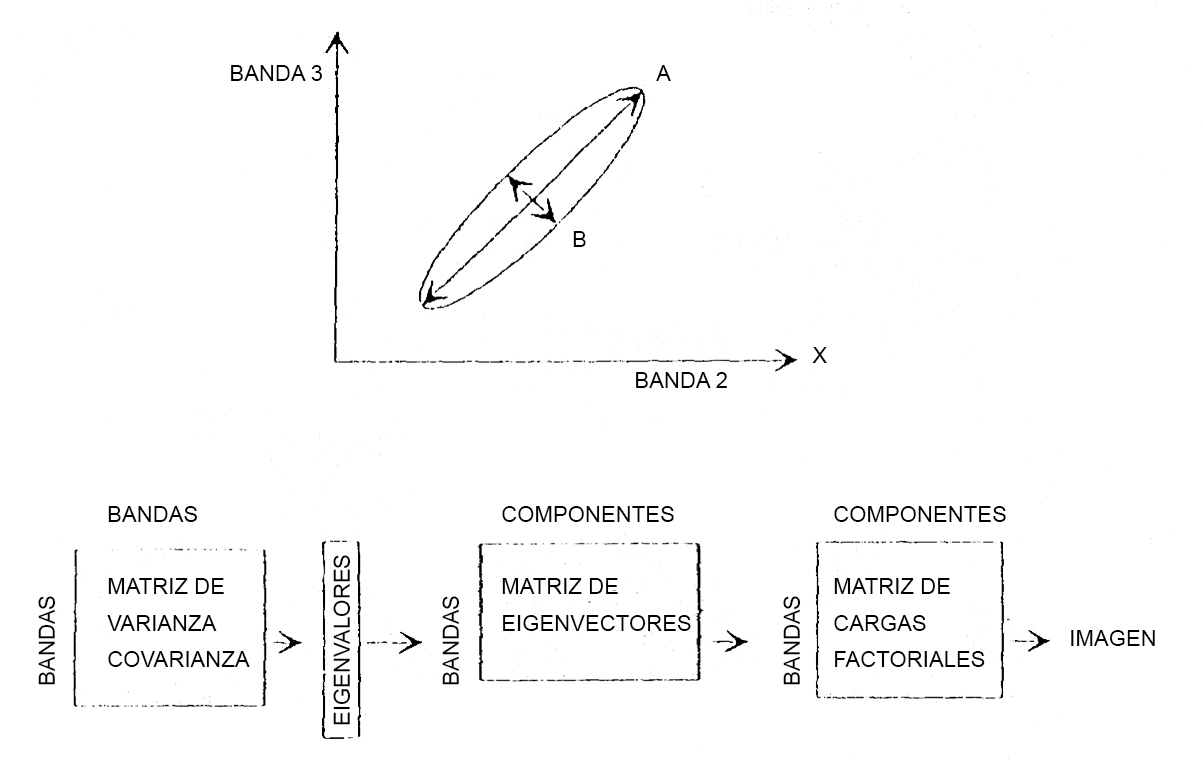
Fuente: Chuvieco, 1995.
El planteamiento conceptual de la transformación señala que un conjunto de n variables definen un espacio vectorial n–dimensional, de manera que las características de un elemento determinado (en caso de una capa ráster será una celda dada) se expresen a través de un vector de n elementos de la forma (x1,x2,...,xn).
El ACP busca definir un cambio de base en ese espacio n–dimensional, de modo que los vectores de la nueva base tengan una relación directa con las direcciones de variabilidad del conjunto de datos. El primer vector de la base señala la dirección de máxima variabilidad, el segundo la segunda dirección de máxima variabilidad, y así sucesivamente. (Olaya, 2014: 567)
De este modo, en la nueva base, la mayor parte de la información va a estar en la dirección del primer vector e irá decreciendo paulatinamente a medida que se vayan tomando los sucesivos vectores de la base.
Al aplicar el cambio de base a un vector (x1,x2,...,xn), se obtiene un nuevo vector (x’1,x’2,...,x’n), expresado en las coordenadas de la nueva base. Puesto que las primeras coordenadas de este nuevo vector se corresponden con las direcciones de máxima variabilidad, podemos tomar solo las primeras p coordenadas (siendo p < n) y tener un vector de la forma (x1,x2,...,xp), sabiendo que haciendo esto estamos perdiendo poca información a pesar de reducir la dimensión del vector original. Estas p coordenadas son los p componentes principales. (Olaya, 2014: 567)
Es necesario señalar que las variables resultantes no pueden utilizarse como las originales al carecer de sentido físico. Asimismo, los vectores finales pueden aportar información útil para determinados análisis. La información que se sitúa sobre los ejes principales va a definir la información que aparece en todas las variables utilizadas; no obstante, la información restante aparecerá solo en alguna de ellas. Esto resulta útil, por ejemplo, para el estudio de los cambios producidos diacrónicamente.
Si tomamos como n variables un conjunto de n medidas de una única variable en n instantes, el análisis de componentes nos permite separar la información común a todos ellos de aquella que solo corresponde a algunos de los mismos. De este modo, podemos analizar una u otra parte de la información según sean los resultados que busquemos. (Olaya, 2014: 568)
Para realizar el cálculo de la matriz del cambio de base que define la transformación, se puede partir de la matriz de covarianzas C o bien de la matriz de correlación ρ, en la que los elementos son los coeficientes de correlación de Pearson:
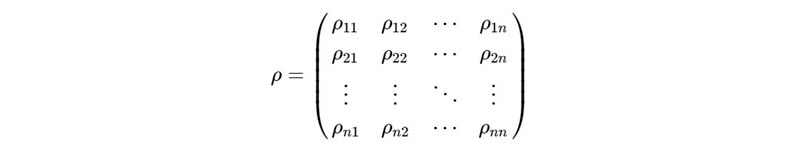
Donde ρij se calcula de acuerdo con:
\[ \rho_{ij} = \sigma_{ij} / \sigma_{ii} \sigma_{jj} \]
Esta matriz se utiliza en lugar de la matriz de covarianzas cuando las unidades en las que se miden las variables no tienen relación entre sí, y es imposible compararlas. Tras obtener la matriz es necesario obtener sus autovalores y autovectores. Los autovectores son los vectores de la nueva base, y sus autovalores asociados se utilizan para establecer el orden en que tienen de considerarse. De este modo, el mayor autovalor se asocia al vector en la dirección de la máxima variabilidad. De igual manera, el de mínimo valor se asocia al vector en la dirección de mínima variabilidad (Olaya, 2014: 568).
Fung, T. y Ledrew, E. (1987), “Application of principal component analysis to change detection”, Photogrammetric Engineering and Remote Sensing, 53(12): 1649-1658.
Otras transformaciones
Como se señalaba con anterioridad, las diferentes aplicaciones informáticas ofrecen una amplia variedad de posibles transformaciones. Estas incluyen transformaciones del espacio de color, los cálculos de textura, las transformaciones térmicas del cuerpo negro y un gran abanico de transformaciones ad hoc que se pueden realizar de forma rápida y efectiva.
Complete la siguiente tabla señalando las principales diferencias entre la fotografía aérea y las imágenes digitales (satelitales):
Fotografía aérea
Imagen satelital
Detección de la escena
Forma de detección de la energía entrante
Registro de longitudes de onda
Métodos de interpretación
Costo económico
Aplicaciones
Realice un análisis de detección de cambios entre estas imágenes, donde la imagen final mostrará solo dos valores: 1 = píxeles de cambio y 0 = píxeles de no cambio. El valor umbral para detectar cambios es < 4.
10
15
3
6
11
12
3
5
13
2016-08-30
13
14
9
6
18
14
0
2
8
2017-08-30
Reflexione y conteste la pregunta:
¿Cuál sería el rango de valores si el número de bits para almacenar cada píxel en una imagen es: a) 2, b) 4, c) 8, d) 16?
3.4. Práctica 3. Análisis visual
Composiciones en color. Identificación de elementos.
El color es uno de los criterios de identificación más importantes en el análisis visual. Las composiciones en color se basan en el proceso aditivo del color, es decir, los píxeles tendrán más intensidad de un determinado color (azul, verde o rojo) cuanto mayor sea su reflectividad en la banda a la que se aplique ese color.
- Observe con atención la lámina 1 (imagen Landsat-7) y responda las siguientes preguntas:
Lámina 1. Imagen Landsat-7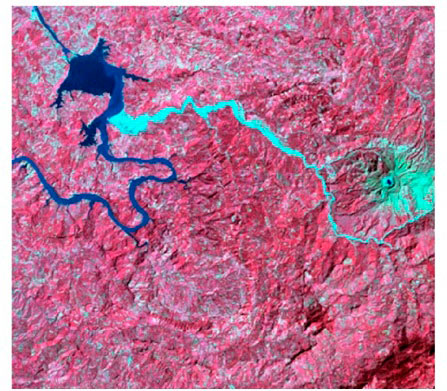 Fuente: <https://landsat.visibleearth.nasa.gov/>
Fuente: <https://landsat.visibleearth.nasa.gov/>Qué asignación de colores (bandas) se ha utilizado en la imagen Landsat-7 de la lámina 1? Elija una respuesta (A, B o C) y explique los porqués de la elección.
- R,G,B => 2,4,3
- R,G,B => 4,3,2
- R,G,B => 5,4,3
Identifique las diferentes cubiertas que aparecen la imagen de la lámina 1.
[Nota: considera la respuesta espectral de las distintas cubiertas en las diferentes longitudes de onda (bandas) y la composición de color utilizada].
- 1:
- 2:
- 3:
- 4:
- 5:
- 6:
Identificación de elementos sobre una imagen
Lámina 2. Imagen Landsat-4 Fuente: <https://eoimages.gsfc.nasa.gov/images/imagerecords/77000/77962/1982_Vandenburg_946x710.jpg>
Fuente: <https://eoimages.gsfc.nasa.gov/images/imagerecords/77000/77962/1982_Vandenburg_946x710.jpg>Encuentre ejemplos de los siguientes elementos/cubiertas sobre la imagen de la lámina 2.
Señale y delimite aproximadamente cada elemento en un programa sencillo de tratamiento de imagen (Paint).
[Nota: utilice el link de la fuente de la imagen para una mejor definición].
- Zona urbana residencial (ajardinada)
- Zona urbana residencial sin jardines
- Zona industrial
- Aeropuerto
- Puerto
- Parque urbano
- Hospital
- Zona forestal
- Campos de cultivo
- Carreteras asfaltadas
- Carreteras sin asfaltar
- Instalaciones deportivas singulares
- Vías de ferrocarril
- Ríos
- Lagos/embalses
Clasificación visual. Generar un mapa de ocupación del suelo mediante análisis visual de la imagen de la lámina 3
Lámina 3. Imagen Landsat-8. Infrarrojo SWIR
Teniendo en cuenta los criterios de identificación del análisis visual de imágenes (tono, textura, color, patrón, etc.), genere una clasificación visual de la imagen de la lámina 3 para obtener un mapa de ocupaciónN del suelo de, al menos, 6 categorías temáticas (leyenda). Después discrimine dichas categorías sobre la imagen delimitando con un programa sencillo (Paint) los límites correspondientes. Al finalizar, comente los criterios de identificación utilizados para cada categoría y las dificultades encontradas en la clasificación.
NPastillaEs posible que, en algunas zonas, la superficie ocupada por una categoría sea inferior a la unidad mínima cartografiable; esas zonas quedarán englobadas en la categoría con mayor representación].
Se puede descargar la imagen para una mayor definición en el siguiente enlace: